Table of Contents
- 13.1. The
MyISAMStorage Engine - 13.2. The
InnoDBStorage Engine - 13.2.1.
InnoDBContact Information - 13.2.2.
InnoDBConfiguration - 13.2.3.
InnoDBStartup Options and System Variables - 13.2.4. Creating and Using
InnoDBTables - 13.2.5. Adding, Removing, or Resizing
InnoDBData and Log Files - 13.2.6. Backing Up and Recovering an
InnoDBDatabase - 13.2.7. Moving an
InnoDBDatabase to Another Machine - 13.2.8. The
InnoDBTransaction Model and Locking - 13.2.9.
InnoDBMulti-Versioning - 13.2.10.
InnoDBTable and Index Structures - 13.2.11.
InnoDBDisk I/O and File Space Management - 13.2.12.
InnoDBError Handling - 13.2.13.
InnoDBPerformance Tuning and Troubleshooting - 13.2.14. Restrictions on
InnoDBTables
- 13.2.1.
- 13.3. The
MERGEStorage Engine - 13.4. The
MEMORY(HEAP) Storage Engine - 13.5. The
BDB(BerkeleyDB) Storage Engine - 13.6. The
EXAMPLEStorage Engine - 13.7. The
FEDERATEDStorage Engine - 13.8. The
ARCHIVEStorage Engine - 13.9. The
CSVStorage Engine - 13.10. The
BLACKHOLEStorage Engine
MySQL supports several storage engines that act as handlers for different table types. MySQL storage engines include both those that handle transaction-safe tables and those that handle nontransaction-safe tables:
MyISAMmanages nontransactional tables. It provides high-speed storage and retrieval, as well as fulltext searching capabilities.MyISAMis supported in all MySQL configurations, and is the default storage engine unless you have configured MySQL to use a different one by default.The
MEMORYstorage engine provides in-memory tables. TheMERGEstorage engine allows a collection of identicalMyISAMtables to be handled as a single table. LikeMyISAM, theMEMORYandMERGEstorage engines handle nontransactional tables, and both are also included in MySQL by default.Note
The
MEMORYstorage engine formerly was known as theHEAPengine.The
InnoDBandBDBstorage engines provide transaction-safe tables. To maintain data integrity,InnoDBalso supportsFOREIGN KEYreferential-integrity constraints.The
EXAMPLEstorage engine is a “stub” engine that does nothing. You can create tables with this engine, but no data can be stored in them or retrieved from them. The purpose of this engine is to serve as an example in the MySQL source code that illustrates how to begin writing new storage engines. As such, it is primarily of interest to developers.NDBCLUSTER(also known asNDB) is the storage engine used by MySQL Cluster to implement tables that are partitioned over many computers. It is available in MySQL 5.0 binary distributions. This storage engine is currently supported on a number of Unix platforms. We intend to add support for this engine on other platforms, including Windows, in future MySQL Cluster releases.MySQL Cluster is covered in a separate chapter of this Manual. See Chapter 17, MySQL Cluster, for more information.
Note
MySQL Cluster users wishing to upgrade from MySQL 5.0 should instead migrate to MySQL Cluster NDB 6.2 or 6.3; these are based on MySQL 5.1 but contain the latest improvements and fixes for
NDBCLUSTER. TheNDBCLUSTERstorage engine is not supported in standard MySQL 5.1 releases.The
ARCHIVEstorage engine is used for storing large amounts of data without indexes with a very small footprint.The
CSVstorage engine stores data in text files using comma-separated values format.The
BLACKHOLEstorage engine accepts but does not store data and retrievals always return an empty set.The
FEDERATEDstorage engine was added in MySQL 5.0.3. This engine stores data in a remote database. Currently, it works with MySQL only, using the MySQL C Client API. In future releases, we intend to enable it to connect to other data sources using other drivers or client connection methods.
To determine which storage engines your server supports by using the
SHOW ENGINES statement. The value in
the Support column indicates whether an engine
can be used. A value of YES,
NO, or DEFAULT indicates that
an engine is available, not available, or avaiable and current set
as the default storage engine.
mysql> SHOW ENGINES\G
*************************** 1. row ***************************
Engine: MyISAM
Support: DEFAULT
Comment: Default engine as of MySQL 3.23 with great performance
*************************** 2. row ***************************
Engine: MEMORY
Support: YES
Comment: Hash based, stored in memory, useful for temporary tables
*************************** 3. row ***************************
Engine: InnoDB
Support: YES
Comment: Supports transactions, row-level locking, and foreign keys
*************************** 4. row ***************************
Engine: BerkeleyDB
Support: NO
Comment: Supports transactions and page-level locking
*************************** 5. row ***************************
Engine: BLACKHOLE
Support: YES
Comment: /dev/null storage engine (anything you write to it disappears)
...
This chapter describes each of the MySQL storage engines except for
NDBCLUSTER, which is covered in
Chapter 17, MySQL Cluster.
For information about storage engine support offered in commercial MySQL Server binaries, see MySQL Enterprise Server 5.1, on the MySQL website. The storage engines available might depend on which edition of Enterprise Server you are using.
For answers to some commonly asked questions about MySQL storage engines, see Section A.2, “MySQL 5.0 FAQ — Storage Engines”.
When you create a new table, you can specify which storage engine to
use by adding an ENGINE or
TYPE table option to the
CREATE TABLE statement:
CREATE TABLE t (i INT) ENGINE = INNODB; CREATE TABLE t (i INT) TYPE = MEMORY;
The older term TYPE is supported as a synonym for
ENGINE for backward compatibility, but
ENGINE is the preferred term and
TYPE is deprecated.
If you omit the ENGINE or TYPE
option, the default storage engine is used. Normally, this is
MyISAM, but you can change it by using the
--default-storage-engine or
--default-table-type server startup
option, or by setting the default-storage-engine
or default-table-type option in the
my.cnf configuration file.
You can set the default storage engine to be used during the current
session by setting the
storage_engine or
table_type variable:
SET storage_engine=MYISAM; SET table_type=BDB;
When MySQL is installed on Windows using the MySQL Configuration
Wizard, the InnoDB storage engine can be selected
as the default instead of MyISAM. See
Section 2.9.4.5, “The Database Usage Dialog”.
To convert a table from one storage engine to another, use an
ALTER TABLE statement that indicates
the new engine:
ALTER TABLE t ENGINE = MYISAM; ALTER TABLE t TYPE = BDB;
See Section 12.1.10, “CREATE TABLE Syntax”, and
Section 12.1.4, “ALTER TABLE Syntax”.
If you try to use a storage engine that is not compiled in or that
is compiled in but deactivated, MySQL instead creates a table using
the default storage engine, usually MyISAM. This
behavior is convenient when you want to copy tables between MySQL
servers that support different storage engines. (For example, in a
replication setup, perhaps your master server supports transactional
storage engines for increased safety, but the slave servers use only
nontransactional storage engines for greater speed.)
This automatic substitution of the default storage engine for unavailable engines can be confusing for new MySQL users. A warning is generated whenever a storage engine is automatically changed.
For new tables, MySQL always creates an .frm
file to hold the table and column definitions. The table's index and
data may be stored in one or more other files, depending on the
storage engine. The server creates the .frm
file above the storage engine level. Individual storage engines
create any additional files required for the tables that they
manage.
A database may contain tables of different types. That is, tables need not all be created with the same storage engine.
Transaction-safe tables (TSTs) have several advantages over nontransaction-safe tables (NTSTs):
They are safer. Even if MySQL crashes or you get hardware problems, you can get your data back, either by automatic recovery or from a backup plus the transaction log.
You can combine many statements and accept them all at the same time with the
COMMITstatement (if autocommit is disabled).You can execute
ROLLBACKto ignore your changes (if autocommit is disabled).If an update fails, all of your changes are reverted. (With nontransaction-safe tables, all changes that have taken place are permanent.)
Transaction-safe storage engines can provide better concurrency for tables that get many updates concurrently with reads.
You can combine transaction-safe and nontransaction-safe tables in
the same statements to get the best of both worlds. However,
although MySQL supports several transaction-safe storage engines,
for best results, you should not mix different storage engines
within a transaction with autocommit disabled. For example, if you
do this, changes to nontransaction-safe tables still are committed
immediately and cannot be rolled back. For information about this
and other problems that can occur in transactions that use mixed
storage engines, see Section 12.4.1, “START TRANSACTION,
COMMIT, and
ROLLBACK Syntax”.
Nontransaction-safe tables have several advantages of their own, all of which occur because there is no transaction overhead:
Much faster
Lower disk space requirements
Less memory required to perform updates
MyISAM is the default storage engine. It is based
on the older ISAM code but has many useful
extensions. (Note that MySQL 5.0 does
not support ISAM.)
Each MyISAM table is stored on disk in three
files. The files have names that begin with the table name and have
an extension to indicate the file type. An .frm
file stores the table format. The data file has an
.MYD (MYData) extension. The
index file has an .MYI
(MYIndex) extension.
To specify explicitly that you want a MyISAM
table, indicate that with an ENGINE table option:
CREATE TABLE t (i INT) ENGINE = MYISAM;
The older term TYPE is supported as a synonym for
ENGINE for backward compatibility, but
ENGINE is the preferred term and
TYPE is deprecated.
Normally, it is unnecesary to use ENGINE to
specify the MyISAM storage engine.
MyISAM is the default engine unless the default
has been changed. To ensure that MyISAM is used
in situations where the default might have been changed, include the
ENGINE option explicitly.
You can check or repair MyISAM tables with the
mysqlcheck client or myisamchk
utility. You can also compress MyISAM tables with
myisampack to take up much less space. See
Section 4.5.3, “mysqlcheck — A Table Maintenance Program”, Section 6.4.1, “Using myisamchk for Crash Recovery”, and
Section 4.6.5, “myisampack — Generate Compressed, Read-Only MyISAM Tables”.
MyISAM tables have the following characteristics:
All data values are stored with the low byte first. This makes the data machine and operating system independent. The only requirements for binary portability are that the machine uses two's-complement signed integers and IEEE floating-point format. These requirements are widely used among mainstream machines. Binary compatibility might not be applicable to embedded systems, which sometimes have peculiar processors.
There is no significant speed penalty for storing data low byte first; the bytes in a table row normally are unaligned and it takes little more processing to read an unaligned byte in order than in reverse order. Also, the code in the server that fetches column values is not time critical compared to other code.
All numeric key values are stored with the high byte first to allow better index compression.
Large files (up to 63-bit file length) are supported on file systems and operating systems that support large files.
There is a limit of 232 (~4.295E+09) rows in a
MyISAMtable. If you build MySQL with the--with-big-tablesoption, the row limitation is increased to (232)2 (1.844E+19) rows. See Section 2.16.2, “Typical configure Options”. Binary distributions for Unix and Linux are built with this option.The maximum number of indexes per
MyISAMtable is 64. This can be changed by recompiling. Beginning with MySQL 5.0.18, you can configure the build by invoking configure with the--with-max-indexes=option, whereNNis the maximum number of indexes to permit perMyISAMtable.Nmust be less than or equal to 128. Before MySQL 5.0.18, you must change the source.The maximum number of columns per index is 16.
The maximum key length is 1000 bytes. This can also be changed by changing the source and recompiling. For the case of a key longer than 250 bytes, a larger key block size than the default of 1024 bytes is used.
When rows are inserted in sorted order (as when you are using an
AUTO_INCREMENTcolumn), the index tree is split so that the high node only contains one key. This improves space utilization in the index tree.Internal handling of one
AUTO_INCREMENTcolumn per table is supported.MyISAMautomatically updates this column forINSERTandUPDATEoperations. This makesAUTO_INCREMENTcolumns faster (at least 10%). Values at the top of the sequence are not reused after being deleted. (When anAUTO_INCREMENTcolumn is defined as the last column of a multiple-column index, reuse of values deleted from the top of a sequence does occur.) TheAUTO_INCREMENTvalue can be reset withALTER TABLEor myisamchk.Dynamic-sized rows are much less fragmented when mixing deletes with updates and inserts. This is done by automatically combining adjacent deleted blocks and by extending blocks if the next block is deleted.
MyISAMsupports concurrent inserts: If a table has no free blocks in the middle of the data file, you canINSERTnew rows into it at the same time that other threads are reading from the table. A free block can occur as a result of deleting rows or an update of a dynamic length row with more data than its current contents. When all free blocks are used up (filled in), future inserts become concurrent again. See Section 7.3.3, “Concurrent Inserts”.You can put the data file and index file in different directories on different physical devices to get more speed with the
DATA DIRECTORYandINDEX DIRECTORYtable options toCREATE TABLE. See Section 12.1.10, “CREATE TABLESyntax”.NULLvalues are allowed in indexed columns. This takes 0–1 bytes per key.Each character column can have a different character set. See Section 9.1, “Character Set Support”.
There is a flag in the
MyISAMindex file that indicates whether the table was closed correctly. If mysqld is started with the--myisam-recoveroption,MyISAMtables are automatically checked when opened, and are repaired if the table wasn't closed properly.myisamchk marks tables as checked if you run it with the
--update-stateoption. myisamchk --fast checks only those tables that don't have this mark.myisamchk --analyze stores statistics for portions of keys, as well as for entire keys.
myisampack can pack
BLOBandVARCHARcolumns.
MyISAM also supports the following features:
Additional resources
A forum dedicated to the
MyISAMstorage engine is available at http://forums.mysql.com/list.php?21.
The following options to mysqld can be used to
change the behavior of MyISAM tables. For
additional information, see Section 5.1.2, “Server Command Options”.
Table 13.1. mysqld MyISAM Option/Variable Reference
| Name | Cmd-Line | Option file | System Var | Status Var | Var Scope | Dynamic |
|---|---|---|---|---|---|---|
| bulk_insert_buffer_size | Yes | Yes | Yes | Both | Yes | |
| concurrent_insert | Yes | Yes | Yes | Global | Yes | |
| delay-key-write | Yes | Yes | Global | Yes | ||
| - Variable: delay_key_write | Yes | Global | Yes | |||
| have_rtree_keys | Yes | Global | No | |||
| key_buffer_size | Yes | Yes | Yes | Global | Yes | |
| log-isam | Yes | Yes | ||||
| myisam-block-size | Yes | Yes | ||||
| myisam_data_pointer_size | Yes | Yes | Yes | Global | Yes | |
| myisam_max_extra_sort_file_size | Yes | Yes | Yes | Global | No | |
| myisam_max_sort_file_size | Yes | Yes | Yes | Global | Yes | |
| myisam-recover | Yes | Yes | ||||
| myisam_recover_options | Yes | Global | No | |||
| myisam_repair_threads | Yes | Yes | Yes | Both | Yes | |
| myisam_sort_buffer_size | Yes | Yes | Yes | Both | Yes | |
| myisam_stats_method | Yes | Yes | Yes | Both | Yes | |
| skip-concurrent-insert | Yes | Yes | ||||
| - Variable: concurrent_insert | ||||||
| tmp_table_size | Yes | Yes | Yes | Both | Yes |
Set the mode for automatic recovery of crashed
MyISAMtables.Don't flush key buffers between writes for any
MyISAMtable.Note
If you do this, you should not access
MyISAMtables from another program (such as from another MySQL server or with myisamchk) when the tables are in use. Doing so risks index corruption. Using--external-lockingdoes not eliminate this risk.
The following system variables affect the behavior of
MyISAM tables. For additional information, see
Section 5.1.3, “Server System Variables”.
The size of the tree cache used in bulk insert optimization.
Note
This is a limit per thread!
The maximum size of the temporary file that MySQL is allowed to use while re-creating a
MyISAMindex (duringREPAIR TABLE,ALTER TABLE, orLOAD DATA INFILE). If the file size would be larger than this value, the index is created using the key cache instead, which is slower. The value is given in bytes.Set the size of the buffer used when recovering tables.
Automatic recovery is activated if you start
mysqld with the
--myisam-recover option. In this
case, when the server opens a MyISAM table, it
checks whether the table is marked as crashed or whether the open
count variable for the table is not 0 and you are running the
server with external locking disabled. If either of these
conditions is true, the following happens:
MySQL Enterprise
Subscribers to MySQL Enterprise Monitor receive notification if
the --myisam-recover option has
not been set. For more information, see
http://www.mysql.com/products/enterprise/advisors.html.
The server checks the table for errors.
If the server finds an error, it tries to do a fast table repair (with sorting and without re-creating the data file).
If the repair fails because of an error in the data file (for example, a duplicate-key error), the server tries again, this time re-creating the data file.
If the repair still fails, the server tries once more with the old repair option method (write row by row without sorting). This method should be able to repair any type of error and has low disk space requirements.
If the recovery wouldn't be able to recover all rows from
previously completed statements and you didn't specify
FORCE in the value of the
--myisam-recover option, automatic
repair aborts with an error message in the error log:
Error: Couldn't repair table: test.g00pages
If you specify FORCE, a warning like this is
written instead:
Warning: Found 344 of 354 rows when repairing ./test/g00pages
Note that if the automatic recovery value includes
BACKUP, the recovery process creates files with
names of the form
tbl_name-datetime.BAK
MyISAM tables use B-tree indexes. You can
roughly calculate the size for the index file as
(key_length+4)/0.67, summed over all keys. This
is for the worst case when all keys are inserted in sorted order
and the table doesn't have any compressed keys.
String indexes are space compressed. If the first index part is a
string, it is also prefix compressed. Space compression makes the
index file smaller than the worst-case figure if a string column
has a lot of trailing space or is a
VARCHAR column that is not always
used to the full length. Prefix compression is used on keys that
start with a string. Prefix compression helps if there are many
strings with an identical prefix.
In MyISAM tables, you can also prefix compress
numbers by specifying the PACK_KEYS=1 table
option when you create the table. Numbers are stored with the high
byte first, so this helps when you have many integer keys that
have an identical prefix.
MyISAM supports three different storage
formats. Two of them, fixed and dynamic format, are chosen
automatically depending on the type of columns you are using. The
third, compressed format, can be created only with the
myisampack utility (see
Section 4.6.5, “myisampack — Generate Compressed, Read-Only MyISAM Tables”).
When you use CREATE TABLE or
ALTER TABLE for a table that has no
BLOB or
TEXT columns, you can force the
table format to FIXED or
DYNAMIC with the ROW_FORMAT
table option.
See Section 12.1.10, “CREATE TABLE Syntax”, for information about
ROW_FORMAT.
You can decompress (unpack) compressed MyISAM
tables using myisamchk
--unpack; see
Section 4.6.3, “myisamchk — MyISAM Table-Maintenance Utility”, for more information.
Static format is the default for MyISAM
tables. It is used when the table contains no variable-length
columns (VARCHAR,
VARBINARY,
BLOB, or
TEXT). Each row is stored using a
fixed number of bytes.
Of the three MyISAM storage formats, static
format is the simplest and most secure (least subject to
corruption). It is also the fastest of the on-disk formats due
to the ease with which rows in the data file can be found on
disk: To look up a row based on a row number in the index,
multiply the row number by the row length to calculate the row
position. Also, when scanning a table, it is very easy to read a
constant number of rows with each disk read operation.
The security is evidenced if your computer crashes while the
MySQL server is writing to a fixed-format
MyISAM file. In this case,
myisamchk can easily determine where each row
starts and ends, so it can usually reclaim all rows except the
partially written one. Note that MyISAM table
indexes can always be reconstructed based on the data rows.
Note
Fixed-length row format is only available for tables without
BLOB or
TEXT columns. Creating a table
with these columns with an explicit
ROW_FORMAT clause will not raise an error
or warning; the format specification will be ignored.
Static-format tables have these characteristics:
CHARandVARCHARcolumns are space-padded to the specified column width, although the column type is not altered. This is also true forNUMERICandDECIMALcolumns created before MySQL 5.0.3.BINARYandVARBINARYcolumns are space-padded to the column width before MySQL 5.0.15. As of 5.0.15,BINARYandVARBINARYcolumns are padded with0x00bytes.Very quick.
Easy to cache.
Easy to reconstruct after a crash, because rows are located in fixed positions.
Reorganization is unnecessary unless you delete a huge number of rows and want to return free disk space to the operating system. To do this, use
OPTIMIZE TABLEor myisamchk -r.Usually require more disk space than dynamic-format tables.
Dynamic storage format is used if a MyISAM
table contains any variable-length columns
(VARCHAR,
VARBINARY,
BLOB, or
TEXT), or if the table was
created with the ROW_FORMAT=DYNAMIC table
option.
Dynamic format is a little more complex than static format because each row has a header that indicates how long it is. A row can become fragmented (stored in noncontiguous pieces) when it is made longer as a result of an update.
You can use OPTIMIZE TABLE or
myisamchk -r to defragment a table. If you
have fixed-length columns that you access or change frequently
in a table that also contains some variable-length columns, it
might be a good idea to move the variable-length columns to
other tables just to avoid fragmentation.
Dynamic-format tables have these characteristics:
All string columns are dynamic except those with a length less than four.
Each row is preceded by a bitmap that indicates which columns contain the empty string (for string columns) or zero (for numeric columns). Note that this does not include columns that contain
NULLvalues. If a string column has a length of zero after trailing space removal, or a numeric column has a value of zero, it is marked in the bitmap and not saved to disk. Nonempty strings are saved as a length byte plus the string contents.Much less disk space usually is required than for fixed-length tables.
Each row uses only as much space as is required. However, if a row becomes larger, it is split into as many pieces as are required, resulting in row fragmentation. For example, if you update a row with information that extends the row length, the row becomes fragmented. In this case, you may have to run
OPTIMIZE TABLEor myisamchk -r from time to time to improve performance. Use myisamchk -ei to obtain table statistics.More difficult than static-format tables to reconstruct after a crash, because rows may be fragmented into many pieces and links (fragments) may be missing.
The expected row length for dynamic-sized rows is calculated using the following expression:
3 + (
number of columns+ 7) / 8 + (number of char columns) + (packed size of numeric columns) + (length of strings) + (number of NULL columns+ 7) / 8There is a penalty of 6 bytes for each link. A dynamic row is linked whenever an update causes an enlargement of the row. Each new link is at least 20 bytes, so the next enlargement probably goes in the same link. If not, another link is created. You can find the number of links using myisamchk -ed. All links may be removed with
OPTIMIZE TABLEor myisamchk -r.
Compressed storage format is a read-only format that is generated with the myisampack tool. Compressed tables can be uncompressed with myisamchk.
Compressed tables have the following characteristics:
Compressed tables take very little disk space. This minimizes disk usage, which is helpful when using slow disks (such as CD-ROMs).
Each row is compressed separately, so there is very little access overhead. The header for a row takes up one to three bytes depending on the biggest row in the table. Each column is compressed differently. There is usually a different Huffman tree for each column. Some of the compression types are:
Suffix space compression.
Prefix space compression.
Numbers with a value of zero are stored using one bit.
If values in an integer column have a small range, the column is stored using the smallest possible type. For example, a
BIGINTcolumn (eight bytes) can be stored as aTINYINTcolumn (one byte) if all its values are in the range from-128to127.If a column has only a small set of possible values, the data type is converted to
ENUM.A column may use any combination of the preceding compression types.
Can be used for fixed-length or dynamic-length rows.
Note
While a compressed table is read only, and you cannot
therefore update or add rows in the table, DDL (Data
Definition Language) operations are still valid. For example,
you may still use DROP to drop the table,
and TRUNCATE to empty the
table.
The file format that MySQL uses to store data has been extensively tested, but there are always circumstances that may cause database tables to become corrupted. The following discussion describes how this can happen and how to handle it.
Even though the MyISAM table format is very
reliable (all changes to a table made by an SQL statement are
written before the statement returns), you can still get
corrupted tables if any of the following events occur:
The mysqld process is killed in the middle of a write.
An unexpected computer shutdown occurs (for example, the computer is turned off).
Hardware failures.
You are using an external program (such as myisamchk) to modify a table that is being modified by the server at the same time.
A software bug in the MySQL or
MyISAMcode.
Typical symptoms of a corrupt table are:
You get the following error while selecting data from the table:
Incorrect key file for table: '...'. Try to repair it
Queries don't find rows in the table or return incomplete results.
You can check the health of a MyISAM table
using the CHECK TABLE statement,
and repair a corrupted MyISAM table with
REPAIR TABLE. When
mysqld is not running, you can also check or
repair a table with the myisamchk command.
See Section 12.5.2.3, “CHECK TABLE Syntax”,
Section 12.5.2.6, “REPAIR TABLE Syntax”, and Section 4.6.3, “myisamchk — MyISAM Table-Maintenance Utility”.
If your tables become corrupted frequently, you should try to
determine why this is happening. The most important thing to
know is whether the table became corrupted as a result of a
server crash. You can verify this easily by looking for a recent
restarted mysqld message in the error log. If
there is such a message, it is likely that table corruption is a
result of the server dying. Otherwise, corruption may have
occurred during normal operation. This is a bug. You should try
to create a reproducible test case that demonstrates the
problem. See Section B.1.4.2, “What to Do If MySQL Keeps Crashing”, and
MySQL
Internals: Porting.
MySQL Enterprise Find out about problems before they occur. Subscribe to the MySQL Enterprise Monitor for expert advice about the state of your servers. For more information, see http://www.mysql.com/products/enterprise/advisors.html.
Each MyISAM index file
(.MYI file) has a counter in the header
that can be used to check whether a table has been closed
properly. If you get the following warning from
CHECK TABLE or
myisamchk, it means that this counter has
gone out of sync:
clients are using or haven't closed the table properly
This warning doesn't necessarily mean that the table is corrupted, but you should at least check the table.
The counter works as follows:
The first time a table is updated in MySQL, a counter in the header of the index files is incremented.
The counter is not changed during further updates.
When the last instance of a table is closed (because a
FLUSH TABLESoperation was performed or because there is no room in the table cache), the counter is decremented if the table has been updated at any point.When you repair the table or check the table and it is found to be okay, the counter is reset to zero.
To avoid problems with interaction with other processes that might check the table, the counter is not decremented on close if it was zero.
In other words, the counter can become incorrect only under these conditions:
A
MyISAMtable is copied without first issuingLOCK TABLESandFLUSH TABLES.MySQL has crashed between an update and the final close. (Note that the table may still be okay, because MySQL always issues writes for everything between each statement.)
A table was modified by myisamchk --recover or myisamchk --update-state at the same time that it was in use by mysqld.
Multiple mysqld servers are using the table and one server performed a
REPAIR TABLEorCHECK TABLEon the table while it was in use by another server. In this setup, it is safe to useCHECK TABLE, although you might get the warning from other servers. However,REPAIR TABLEshould be avoided because when one server replaces the data file with a new one, this is not known to the other servers.In general, it is a bad idea to share a data directory among multiple servers. See Section 5.6, “Running Multiple MySQL Servers on the Same Machine”, for additional discussion.
- 13.2.1.
InnoDBContact Information - 13.2.2.
InnoDBConfiguration - 13.2.3.
InnoDBStartup Options and System Variables - 13.2.4. Creating and Using
InnoDBTables - 13.2.5. Adding, Removing, or Resizing
InnoDBData and Log Files - 13.2.6. Backing Up and Recovering an
InnoDBDatabase - 13.2.7. Moving an
InnoDBDatabase to Another Machine - 13.2.8. The
InnoDBTransaction Model and Locking - 13.2.9.
InnoDBMulti-Versioning - 13.2.10.
InnoDBTable and Index Structures - 13.2.11.
InnoDBDisk I/O and File Space Management - 13.2.12.
InnoDBError Handling - 13.2.13.
InnoDBPerformance Tuning and Troubleshooting - 13.2.14. Restrictions on
InnoDBTables
InnoDB is a transaction-safe (ACID compliant)
storage engine for MySQL that has commit, rollback, and
crash-recovery capabilities to protect user data.
InnoDB row-level locking (without escalation to
coarser granularity locks) and Oracle-style consistent nonlocking
reads increase multi-user concurrency and performance.
InnoDB stores user data in clustered indexes to
reduce I/O for common queries based on primary keys. To maintain
data integrity, InnoDB also supports
FOREIGN KEY referential-integrity constraints.
You can freely mix InnoDB tables with tables from
other MySQL storage engines, even within the same statement.
To determine whether your server supports InnoDB
use the SHOW ENGINES statement. See
Section 12.5.5.13, “SHOW ENGINES Syntax”.
InnoDB has been designed for maximum performance
when processing large data volumes. Its CPU efficiency is probably
not matched by any other disk-based relational database engine.
The InnoDB storage engine maintains its own
buffer pool for caching data and indexes in main memory.
InnoDB stores its tables and indexes in a
tablespace, which may consist of several files (or raw disk
partitions). This is different from, for example,
MyISAM tables where each table is stored using
separate files. InnoDB tables can be very large
even on operating systems where file size is limited to 2GB.
The Windows Essentials installer makes InnoDB the
MySQL default storage engine on Windows, if the server being
installed supports InnoDB.
InnoDB is used in production at numerous large
database sites requiring high performance. The famous Internet news
site Slashdot.org runs on InnoDB. Mytrix, Inc.
stores more than 1TB of data in InnoDB, and
another site handles an average load of 800 inserts/updates per
second in InnoDB.
InnoDB is published under the same GNU GPL
License Version 2 (of June 1991) as MySQL. For more information on
MySQL licensing, see
http://www.mysql.com/company/legal/licensing/.
Additional resources
A forum dedicated to the
InnoDBstorage engine is available at http://forums.mysql.com/list.php?22.Innobase Oy also hosts several forums, available at http://forums.innodb.com.
InnoDB Hot Backup enables you to back up a running MySQL database, including
InnoDBandMyISAMtables, with minimal disruption to operations while producing a consistent snapshot of the database. When InnoDB Hot Backup is copyingInnoDBtables, reads and writes to bothInnoDBandMyISAMtables can continue. During the copying ofMyISAMtables, reads (but not writes) to those tables are permitted. In addition, InnoDB Hot Backup supports creating compressed backup files, and performing backups of subsets ofInnoDBtables. In conjunction with MySQL’s binary log, users can perform point-in-time recovery. InnoDB Hot Backup is commercially licensed by Innobase Oy. For a more complete description of InnoDB Hot Backup, see http://www.innodb.com/hot-backup/features/ or download the documentation from http://www.innodb.com/doc/hot_backup/manual.html. You can order trial, term, and perpetual licenses from Innobase at http://www.innodb.com/hot-backup/order/.
Contact information for Innobase Oy, producer of the
InnoDB engine:
Web site: http://www.innodb.com/
Email: innodb_sales_ww at oracle.com or use
this contact form:
http://www.innodb.com/contact-form
Phone:
+358-9-6969 3250 (office, Heikki Tuuri) +358-40-5617367 (mobile, Heikki Tuuri) +358-40-5939732 (mobile, Satu Sirén)
Address:
Innobase Oy Inc. World Trade Center Helsinki Aleksanterinkatu 17 P.O.Box 800 00101 Helsinki Finland
If you do not want to use InnoDB tables, start
the server with the --skip-innodb
option to disable the InnoDB startup engine.
Caution
InnoDB is a transaction-safe (ACID compliant)
storage engine for MySQL that has commit, rollback, and
crash-recovery capabilities to protect user data.
However, it cannot do so if the
underlying operating system or hardware does not work as
advertised. Many operating systems or disk subsystems may delay
or reorder write operations to improve performance. On some
operating systems, the very fsync() system
call that should wait until all unwritten data for a file has
been flushed might actually return before the data has been
flushed to stable storage. Because of this, an operating system
crash or a power outage may destroy recently committed data, or
in the worst case, even corrupt the database because of write
operations having been reordered. If data integrity is important
to you, you should perform some “pull-the-plug”
tests before using anything in production. On Mac OS X 10.3 and
up, InnoDB uses a special
fcntl() file flush method. Under Linux, it is
advisable to disable the write-back
cache.
On ATA/SATA disk drives, a command such hdparm -W0
/dev/hda may work to disable the write-back cache.
Beware that some drives or disk
controllers may be unable to disable the write-back
cache.
Two important disk-based resources managed by the
InnoDB storage engine are its tablespace data
files and its log files. If you specify no
InnoDB configuration options, MySQL creates an
auto-extending 10MB data file named ibdata1
and two 5MB log files named ib_logfile0 and
ib_logfile1 in the MySQL data directory. To
get good performance, you should explicitly provide
InnoDB parameters as discussed in the following
examples. Naturally, you should edit the settings to suit your
hardware and requirements.
Caution
It is not a good idea to configure InnoDB to
use data files or log files on NFS volumes. Otherwise, the files
might be locked by other processes and become unavailable for
use by MySQL.
MySQL Enterprise For advice on settings suitable to your specific circumstances, subscribe to the MySQL Enterprise Monitor. For more information, see http://www.mysql.com/products/enterprise/advisors.html.
The examples shown here are representative. See
Section 13.2.3, “InnoDB Startup Options and System Variables” for additional information
about InnoDB-related configuration parameters.
To set up the InnoDB tablespace files, use the
innodb_data_file_path option in
the [mysqld] section of the
my.cnf option file. On Windows, you can use
my.ini instead. The value of
innodb_data_file_path should be a
list of one or more data file specifications. If you name more
than one data file, separate them by semicolon
(“;”) characters:
innodb_data_file_path=datafile_spec1[;datafile_spec2]...
For example, the following setting explicitly creates a tablespace having the same characteristics as the default:
[mysqld] innodb_data_file_path=ibdata1:10M:autoextend
This setting configures a single 10MB data file named
ibdata1 that is auto-extending. No location
for the file is given, so by default, InnoDB
creates it in the MySQL data directory.
Sizes are specified using K,
M, or G suffix letters to
indicate units of KB, MB, or GB.
A tablespace containing a fixed-size 50MB data file named
ibdata1 and a 50MB auto-extending file named
ibdata2 in the data directory can be
configured like this:
[mysqld] innodb_data_file_path=ibdata1:50M;ibdata2:50M:autoextend
The full syntax for a data file specification includes the file name, its size, and several optional attributes:
file_name:file_size[:autoextend[:max:max_file_size]]
The autoextend and max
attributes can be used only for the last data file in the
innodb_data_file_path line.
If you specify the autoextend option for the
last data file, InnoDB extends the data file if
it runs out of free space in the tablespace. The increment is 8MB
at a time by default. To modify the increment, change the
innodb_autoextend_increment
system variable.
If the disk becomes full, you might want to add another data file
on another disk. For tablespace reconfiguration instructions, see
Section 13.2.5, “Adding, Removing, or Resizing InnoDB Data and Log
Files”.
InnoDB is not aware of the file system maximum
file size, so be cautious on file systems where the maximum file
size is a small value such as 2GB. To specify a maximum size for
an auto-extending data file, use the max
attribute following the autoextend attribute.
The following configuration allows ibdata1 to
grow up to a limit of 500MB:
[mysqld] innodb_data_file_path=ibdata1:10M:autoextend:max:500M
InnoDB creates tablespace files in the MySQL
data directory by default. To specify a location explicitly, use
the innodb_data_home_dir option.
For example, to use two files named ibdata1
and ibdata2 but create them in the
/ibdata directory, configure
InnoDB like this:
[mysqld] innodb_data_home_dir = /ibdata innodb_data_file_path=ibdata1:50M;ibdata2:50M:autoextend
Note
InnoDB does not create directories, so make
sure that the /ibdata directory exists
before you start the server. This is also true of any log file
directories that you configure. Use the Unix or DOS
mkdir command to create any necessary
directories.
Make sure that the MySQL server has the proper access rights to create files in the data directory. More generally, the server must have access rights in any directory where it needs to create data files or log files.
InnoDB forms the directory path for each data
file by textually concatenating the value of
innodb_data_home_dir to the data
file name, adding a path name separator (slash or backslash)
between values if necessary. If the
innodb_data_home_dir option is
not mentioned in my.cnf at all, the default
value is the “dot” directory ./,
which means the MySQL data directory. (The MySQL server changes
its current working directory to its data directory when it begins
executing.)
If you specify
innodb_data_home_dir as an empty
string, you can specify absolute paths for the data files listed
in the innodb_data_file_path
value. The following example is equivalent to the preceding one:
[mysqld] innodb_data_home_dir = innodb_data_file_path=/ibdata/ibdata1:50M;/ibdata/ibdata2:50M:autoextend
A simple my.cnf
example. Suppose that you have a computer with 512MB
RAM and one hard disk. The following example shows possible
configuration parameters in my.cnf or
my.ini for InnoDB,
including the autoextend attribute. The example
suits most users, both on Unix and Windows, who do not want to
distribute InnoDB data files and log files onto
several disks. It creates an auto-extending data file
ibdata1 and two InnoDB log
files ib_logfile0 and
ib_logfile1 in the MySQL data directory.
[mysqld] # You can write your other MySQL server options here # ... # Data files must be able to hold your data and indexes. # Make sure that you have enough free disk space. innodb_data_file_path = ibdata1:10M:autoextend # # Set buffer pool size to 50-80% of your computer's memory innodb_buffer_pool_size=256M innodb_additional_mem_pool_size=20M # # Set the log file size to about 25% of the buffer pool size innodb_log_file_size=64M innodb_log_buffer_size=8M # innodb_flush_log_at_trx_commit=1
Note that data files must be less than 2GB in some file systems. The combined size of the log files must be less than 4GB. The combined size of data files must be at least 10MB.
When you create an InnoDB tablespace for the
first time, it is best that you start the MySQL server from the
command prompt. InnoDB then prints the
information about the database creation to the screen, so you can
see what is happening. For example, on Windows, if
mysqld is located in C:\Program
Files\MySQL\MySQL Server 5.0\bin, you can
start it like this:
C:\> "C:\Program Files\MySQL\MySQL Server 5.0\bin\mysqld" --console
If you do not send server output to the screen, check the server's
error log to see what InnoDB prints during the
startup process.
For an example of what the information displayed by
InnoDB should look like, see
Section 13.2.2.3, “Creating the InnoDB Tablespace”.
You can place InnoDB options in the
[mysqld] group of any option file that your
server reads when it starts. The locations for option files are
described in Section 4.2.3.3, “Using Option Files”.
If you installed MySQL on Windows using the installation and
configuration wizards, the option file will be the
my.ini file located in your MySQL
installation directory. See
Section 2.9.4.1, “Starting the MySQL Server Instance Configuration Wizard”.
If your PC uses a boot loader where the C:
drive is not the boot drive, your only option is to use the
my.ini file in your Windows directory
(typically C:\WINDOWS). You can use the
SET command at the command prompt in a console
window to print the value of WINDIR:
C:\> SET WINDIR
windir=C:\WINDOWS
To make sure that mysqld reads options only
from a specific file, use the
--defaults-file option as the
first option on the command line when starting the server:
mysqld --defaults-file=your_path_to_my_cnf
An advanced my.cnf
example. Suppose that you have a Linux computer with
2GB RAM and three 60GB hard disks at directory paths
/, /dr2 and
/dr3. The following example shows possible
configuration parameters in my.cnf for
InnoDB.
[mysqld] # You can write your other MySQL server options here # ... innodb_data_home_dir = # # Data files must be able to hold your data and indexes innodb_data_file_path = /ibdata/ibdata1:2000M;/dr2/ibdata/ibdata2:2000M:autoextend # # Set buffer pool size to 50-80% of your computer's memory, # but make sure on Linux x86 total memory usage is < 2GB innodb_buffer_pool_size=1G innodb_additional_mem_pool_size=20M innodb_log_group_home_dir = /dr3/iblogs # # Set the log file size to about 25% of the buffer pool size innodb_log_file_size=250M innodb_log_buffer_size=8M # innodb_flush_log_at_trx_commit=1 innodb_lock_wait_timeout=50 # # Uncomment the next line if you want to use it #innodb_thread_concurrency=5
In some cases, database performance improves if the data is not
all placed on the same physical disk. Putting log files on a
different disk from data is very often beneficial for performance.
The example illustrates how to do this. It places the two data
files on different disks and places the log files on the third
disk. InnoDB fills the tablespace beginning
with the first data file. You can also use raw disk partitions
(raw devices) as InnoDB data files, which may
speed up I/O. See Section 13.2.2.2, “Using Raw Devices for the Shared Tablespace”.
Warning
On 32-bit GNU/Linux x86, you must be careful not to set memory
usage too high. glibc may allow the process
heap to grow over thread stacks, which crashes your server. It
is a risk if the value of the following expression is close to
or exceeds 2GB:
innodb_buffer_pool_size + key_buffer_size + max_connections*(sort_buffer_size+read_buffer_size+binlog_cache_size) + max_connections*2MB
Each thread uses a stack (often 2MB, but only 256KB in MySQL
binaries provided by Sun Microsystems, Inc.) and in the worst
case also uses sort_buffer_size +
read_buffer_size additional memory.
By compiling MySQL yourself, you can use up to 64GB of physical
memory in 32-bit Windows. See the description for
innodb_buffer_pool_awe_mem_mb
in Section 13.2.3, “InnoDB Startup Options and System Variables”.
Tuning other mysqld server parameters. The following values are typical and suit most users:
[mysqld]
skip-external-locking
max_connections=200
read_buffer_size=1M
sort_buffer_size=1M
#
# Set key_buffer to 5 - 50% of your RAM depending on how much
# you use MyISAM tables, but keep key_buffer_size + InnoDB
# buffer pool size < 80% of your RAM
key_buffer_size=value
On Linux, if the kernel is enabled for large page support,
InnoDB can use large pages to allocate memory
for its buffer pool and additional memory pool. See
Section 7.5.9, “Enabling Large Page Support”.
You can store each InnoDB table and its
indexes in its own file. This feature is called “multiple
tablespaces” because in effect each table has its own
tablespace.
Using multiple tablespaces can be beneficial to users who want
to move specific tables to separate physical disks or who wish
to restore backups of single tables quickly without interrupting
the use of other InnoDB tables.
To enable multiple tablespaces, start the server with the
--innodb_file_per_table option.
For example, add a line to the [mysqld]
section of my.cnf:
[mysqld] innodb_file_per_table
With multiple tablespaces enabled, InnoDB
stores each newly created table into its own
tbl_name.ibdMyISAM storage engine
does, but MyISAM divides the table into a
tbl_name.MYDtbl_name.MYIInnoDB, the data and the
indexes are stored together in the .ibd
file. The
tbl_name.frm
You cannot freely move .ibd files between
database directories as you can with MyISAM
table files. This is because the table definition that is stored
in the InnoDB shared tablespace includes the
database name, and because InnoDB must
preserve the consistency of transaction IDs and log sequence
numbers.
If you remove the
innodb_file_per_table line from
my.cnf and restart the server,
InnoDB creates tables inside the shared
tablespace files again.
The --innodb_file_per_table
option affects only table creation, not access to existing
tables. If you start the server with this option, new tables are
created using .ibd files, but you can still
access tables that exist in the shared tablespace. If you start
the server without this option, new tables are created in the
shared tablespace, but you can still access any tables that were
created using multiple tablespaces.
Note
InnoDB always needs the shared tablespace
because it puts its internal data dictionary and undo logs
there. The .ibd files are not sufficient
for InnoDB to operate.
To move an .ibd file and the associated
table from one database to another, use a
RENAME TABLE statement:
RENAME TABLEdb1.tbl_nameTOdb2.tbl_name;
If you have a “clean” backup of an
.ibd file, you can restore it to the MySQL
installation from which it originated as follows:
Issue this
ALTER TABLEstatement to delete the current.ibdfile:ALTER TABLE
tbl_nameDISCARD TABLESPACE;Copy the backup
.ibdfile to the proper database directory.Issue this
ALTER TABLEstatement to tellInnoDBto use the new.ibdfile for the table:ALTER TABLE
tbl_nameIMPORT TABLESPACE;
In this context, a “clean”
.ibd file backup is one for which the
following requirements are satisfied:
There are no uncommitted modifications by transactions in the
.ibdfile.There are no unmerged insert buffer entries in the
.ibdfile.Purge has removed all delete-marked index records from the
.ibdfile.mysqld has flushed all modified pages of the
.ibdfile from the buffer pool to the file.
You can make a clean backup .ibd file using
the following method:
Stop all activity from the mysqld server and commit all transactions.
Wait until
SHOW ENGINE INNODB STATUSshows that there are no active transactions in the database, and the main thread status ofInnoDBisWaiting for server activity. Then you can make a copy of the.ibdfile.
Another method for making a clean copy of an
.ibd file is to use the commercial
InnoDB Hot Backup tool:
Use InnoDB Hot Backup to back up the
InnoDBinstallation.Start a second mysqld server on the backup and let it clean up the
.ibdfiles in the backup.
You can use raw disk partitions as data files in the shared tablespace. By using a raw disk, you can perform nonbuffered I/O on Windows and on some Unix systems without file system overhead. This may improve performance, but you are advised to perform tests with and without raw partitions to verify whether this is actually so on your system.
When you create a new data file, you must put the keyword
newraw immediately after the data file size
in innodb_data_file_path. The
partition must be at least as large as the size that you
specify. Note that 1MB in InnoDB is 1024
× 1024 bytes, whereas 1MB in disk specifications usually
means 1,000,000 bytes.
[mysqld] innodb_data_home_dir= innodb_data_file_path=/dev/hdd1:3Gnewraw;/dev/hdd2:2Gnewraw
The next time you start the server, InnoDB
notices the newraw keyword and initializes
the new partition. However, do not create or change any
InnoDB tables yet. Otherwise, when you next
restart the server, InnoDB reinitializes the
partition and your changes are lost. (As a safety measure
InnoDB prevents users from modifying data
when any partition with newraw is specified.)
After InnoDB has initialized the new
partition, stop the server, change newraw in
the data file specification to raw:
[mysqld] innodb_data_home_dir= innodb_data_file_path=/dev/hdd1:5Graw;/dev/hdd2:2Graw
Then restart the server and InnoDB allows
changes to be made.
On Windows, you can allocate a disk partition as a data file like this:
[mysqld] innodb_data_home_dir= innodb_data_file_path=//./D::10Gnewraw
The //./ corresponds to the Windows syntax
of \\.\ for accessing physical drives.
When you use a raw disk partition, be sure that it has
permissions that allow read and write access by the account used
for running the MySQL server. For example, if you run the server
as the mysql user, the partition must allow
read and write access to mysql. If you run
the server with the --memlock
option, the server must be run as root, so
the partition must allow access to root.
Suppose that you have installed MySQL and have edited your
option file so that it contains the necessary
InnoDB configuration parameters. Before
starting MySQL, you should verify that the directories you have
specified for InnoDB data files and log files
exist and that the MySQL server has access rights to those
directories. InnoDB does not create
directories, only files. Check also that you have enough disk
space for the data and log files.
It is best to run the MySQL server mysqld
from the command prompt when you first start the server with
InnoDB enabled, not from
mysqld_safe or as a Windows service. When you
run from a command prompt you see what mysqld
prints and what is happening. On Unix, just invoke
mysqld. On Windows, start
mysqld with the
--console option to direct the
output to the console window.
When you start the MySQL server after initially configuring
InnoDB in your option file,
InnoDB creates your data files and log files,
and prints something like this:
InnoDB: The first specified datafile /home/heikki/data/ibdata1 did not exist: InnoDB: a new database to be created! InnoDB: Setting file /home/heikki/data/ibdata1 size to 134217728 InnoDB: Database physically writes the file full: wait... InnoDB: datafile /home/heikki/data/ibdata2 did not exist: new to be created InnoDB: Setting file /home/heikki/data/ibdata2 size to 262144000 InnoDB: Database physically writes the file full: wait... InnoDB: Log file /home/heikki/data/logs/ib_logfile0 did not exist: new to be created InnoDB: Setting log file /home/heikki/data/logs/ib_logfile0 size to 5242880 InnoDB: Log file /home/heikki/data/logs/ib_logfile1 did not exist: new to be created InnoDB: Setting log file /home/heikki/data/logs/ib_logfile1 size to 5242880 InnoDB: Doublewrite buffer not found: creating new InnoDB: Doublewrite buffer created InnoDB: Creating foreign key constraint system tables InnoDB: Foreign key constraint system tables created InnoDB: Started mysqld: ready for connections
At this point InnoDB has initialized its
tablespace and log files. You can connect to the MySQL server
with the usual MySQL client programs like
mysql. When you shut down the MySQL server
with mysqladmin shutdown, the output is like
this:
010321 18:33:34 mysqld: Normal shutdown 010321 18:33:34 mysqld: Shutdown Complete InnoDB: Starting shutdown... InnoDB: Shutdown completed
You can look at the data file and log directories and you see the files created there. When MySQL is started again, the data files and log files have been created already, so the output is much briefer:
InnoDB: Started mysqld: ready for connections
If you add the
innodb_file_per_table option to
my.cnf, InnoDB stores
each table in its own .ibd file in the same
MySQL database directory where the .frm
file is created. See Section 13.2.2.1, “Using Per-Table Tablespaces”.
If InnoDB prints an operating system error
during a file operation, usually the problem has one of the
following causes:
You did not create the
InnoDBdata file directory or theInnoDBlog directory.mysqld does not have access rights to create files in those directories.
mysqld cannot read the proper
my.cnformy.inioption file, and consequently does not see the options that you specified.The disk is full or a disk quota is exceeded.
You have created a subdirectory whose name is equal to a data file that you specified, so the name cannot be used as a file name.
There is a syntax error in the
innodb_data_home_dirorinnodb_data_file_pathvalue.
If something goes wrong when InnoDB attempts
to initialize its tablespace or its log files, you should delete
all files created by InnoDB. This means all
ibdata files and all
ib_logfile files. In case you have already
created some InnoDB tables, delete the
corresponding .frm files for these tables
(and any .ibd files if you are using
multiple tablespaces) from the MySQL database directories as
well. Then you can try the InnoDB database
creation again. It is best to start the MySQL server from a
command prompt so that you see what is happening.
This section describes the InnoDB-related
command options and system variables. System variables that are
true or false can be enabled at server startup by naming them, or
disabled by using a --skip prefix. For example,
to enable or disable InnoDB checksums, you can
use --innodb_checksums or
--skip-innodb_checksums
on the command line, or
innodb_checksums or
skip-innodb_checksums in an option file. System
variables that take a numeric value can be specified as
--
on the command line or as
var_name=valuevar_name=value
MySQL Enterprise The MySQL Enterprise Monitor provides expert advice on InnoDB start-up options and related system variables. For more information, see http://www.mysql.com/products/enterprise/advisors.html.
Table 13.2. mysqld InnoDB Option/Variable Reference
InnoDB command options:
Enables the
InnoDBstorage engine, if the server was compiled withInnoDBsupport. Use--skip-innodbto disableInnoDB.Controls whether
InnoDBcreates a file namedinnodb_status.in the MySQL data directory. If enabled,<pid>InnoDBperiodically writes the output ofSHOW ENGINE INNODB STATUSto this file.By default, the file is not created. To create it, start mysqld with the
--innodb_status_file=1option. The file is deleted during normal shutdown.
InnoDB system variables:
Whether InnoDB adaptive hash indexes are enabled or disabled (see Section 13.2.10.4, “Adaptive Hash Indexes”). This variable is enabled by default. Use
--skip-innodb_adaptive_hash_indexat server startup to disable it. This variable was added in MySQL 5.0.52.innodb_additional_mem_pool_sizeThe size in bytes of a memory pool
InnoDBuses to store data dictionary information and other internal data structures. The more tables you have in your application, the more memory you need to allocate here. IfInnoDBruns out of memory in this pool, it starts to allocate memory from the operating system and writes warning messages to the MySQL error log. The default value is 1MB.The increment size (in MB) for extending the size of an auto-extending tablespace file when it becomes full. The default value is 8.
The size of the buffer pool (in MB), if it is placed in the AWE memory. If it is greater than 0,
innodb_buffer_pool_sizeis the window in the 32-bit address space of mysqld whereInnoDBmaps that AWE memory. A good value forinnodb_buffer_pool_sizeis 500MB. The maximum possible value is 63000.To take advantage of AWE memory, you will need to recompile MySQL yourself. The current project settings needed for doing this can be found in the
innobase/os/os0proc.csource file.This variable is relevant only in 32-bit Windows. If your 32-bit Windows operating system supports more than 4GB memory, using so-called “Address Windowing Extensions,” you can allocate the
InnoDBbuffer pool into the AWE physical memory using this variable.The size in bytes of the memory buffer
InnoDBuses to cache data and indexes of its tables. The default value is 8MB. The larger you set this value, the less disk I/O is needed to access data in tables. On a dedicated database server, you may set this to up to 80% of the machine physical memory size. However, do not set it too large because competition for physical memory might cause paging in the operating system.InnoDBcan use checksum validation on all pages read from the disk to ensure extra fault tolerance against broken hardware or data files. This validation is enabled by default. However, under some rare circumstances (such as when running benchmarks) this extra safety feature is unneeded and can be disabled with--skip-innodb_checksums. This variable was added in MySQL 5.0.3.The number of threads that can commit at the same time. A value of 0 (the default) allows any number of transactions to commit simultaneously. This variable was added in MySQL 5.0.12.
The number of threads that can enter
InnoDBconcurrently is determined by theinnodb_thread_concurrencyvariable. A thread is placed in a queue when it tries to enterInnoDBif the number of threads has already reached the concurrency limit. When a thread is allowed to enterInnoDB, it is given a number of “free tickets” equal to the value ofinnodb_concurrency_tickets, and the thread can enter and leaveInnoDBfreely until it has used up its tickets. After that point, the thread again becomes subject to the concurrency check (and possible queuing) the next time it tries to enterInnoDB. The default value is 500. This variable was added in MySQL 5.0.3.The paths to individual data files and their sizes. The full directory path to each data file is formed by concatenating
innodb_data_home_dirto each path specified here. The file sizes are specified in KB, MB, or GB (1024MB) by appendingK,M, orGto the size value. The sum of the sizes of the files must be at least 10MB. If you do not specifyinnodb_data_file_path, the default behavior is to create a single 10MB auto-extending data file namedibdata1. The size limit of individual files is determined by your operating system. You can set the file size to more than 4GB on those operating systems that support big files. You can also use raw disk partitions as data files. For detailed information on configuringInnoDBtablespace files, see Section 13.2.2, “InnoDBConfiguration”.The common part of the directory path for all
InnoDBdata files. The default value is the MySQL data directory. If you specify the value as an empty string, you can use absolute file paths ininnodb_data_file_path.If this variable is enabled (the default),
InnoDBstores all data twice, first to the doublewrite buffer, and then to the actual data files. This variable can be turned off with--skip-innodb_doublewritefor benchmarks or cases when top performance is needed rather than concern for data integrity or possible failures. This variable was added in MySQL 5.0.3.The
InnoDBshutdown mode. By default, the value is 1, which causes a “fast” shutdown (the normal type of shutdown). If the value is 0,InnoDBdoes a full purge and an insert buffer merge before a shutdown. These operations can take minutes, or even hours in extreme cases. If the value is 1,InnoDBskips these operations at shutdown. If the value is 2,InnoDBwill just flush its logs and then shut down cold, as if MySQL had crashed; no committed transaction will be lost, but crash recovery will be done at the next startup. The value of 2 can be used as of MySQL 5.0.5, except that it cannot be used on NetWare.The number of file I/O threads in
InnoDB. Normally, this should be left at the default value of 4, but disk I/O on Windows may benefit from a larger number. On Unix, increasing the number has no effect;InnoDBalways uses the default value.If
innodb_file_per_tableis disabled (the default),InnoDBcreates tables in the shared tablespace. Ifinnodb_file_per_tableis enabled,InnoDBcreates each new table using its own.ibdfile for storing data and indexes, rather than in the shared tablespace. See Section 13.2.2.1, “Using Per-Table Tablespaces”.innodb_flush_log_at_trx_commitIf the value of
innodb_flush_log_at_trx_commitis 0, the log buffer is written out to the log file once per second and the flush to disk operation is performed on the log file, but nothing is done at a transaction commit. When the value is 1 (the default), the log buffer is written out to the log file at each transaction commit and the flush to disk operation is performed on the log file. When the value is 2, the log buffer is written out to the file at each commit, but the flush to disk operation is not performed on it. However, the flushing on the log file takes place once per second also when the value is 2. Note that the once-per-second flushing is not 100% guaranteed to happen every second, due to process scheduling issues.The default value of 1 is the value required for ACID compliance. You can achieve better performance by setting the value different from 1, but then you can lose at most one second worth of transactions in a crash. With a value of 0, any mysqld process crash can erase the last second of transactions. With a value of 2, then only an operating system crash or a power outage can erase the last second of transactions. However,
InnoDB's crash recovery is not affected and thus crash recovery does work regardless of the value.For the greatest possible durability and consistency in a replication setup using
InnoDBwith transactions, you should useinnodb_flush_log_at_trx_commit=1,sync_binlog=1, and, before MySQL 5.0.3,innodb_safe_binlogin your master servermy.cnffile. (innodb_safe_binlogis not needed from 5.0.3 on.)Caution
Many operating systems and some disk hardware fool the flush-to-disk operation. They may tell mysqld that the flush has taken place, even though it has not. Then the durability of transactions is not guaranteed even with the setting 1, and in the worst case a power outage can even corrupt the
InnoDBdatabase. Using a battery-backed disk cache in the SCSI disk controller or in the disk itself speeds up file flushes, and makes the operation safer. You can also try using the Unix command hdparm to disable the caching of disk writes in hardware caches, or use some other command specific to the hardware vendor.If set to
fdatasync(the default),InnoDBusesfsync()to flush both the data and log files. If set toO_DSYNC,InnoDBusesO_SYNCto open and flush the log files, andfsync()to flush the data files. IfO_DIRECTis specified (available on some GNU/Linux versions, FreeBSD, and Solaris),InnoDBusesO_DIRECT(ordirectio()on Solaris) to open the data files, and usesfsync()to flush both the data and log files. Note thatInnoDBusesfsync()instead offdatasync(), and it does not useO_DSYNCby default because there have been problems with it on many varieties of Unix. This variable is relevant only for Unix. On Windows, the flush method is alwaysasync_unbufferedand cannot be changed.Different values of this variable can have a marked effect on
InnoDBperformance. For example, on some systems whereInnoDBdata and log files are located on a SAN, it has been found that settinginnodb_flush_methodtoO_DIRECTcan degrade performance of simpleSELECTstatements by a factor of three.The crash recovery mode. Possible values are from 0 to 6. The meanings of these values are described in Section 13.2.6.2, “Forcing
InnoDBRecovery”.Warning
This variable should be set greater than 0 only in an emergency situation when you want to dump your tables from a corrupt database! As a safety measure,
InnoDBprevents any changes to its data when this variable is greater than 0.The timeout in seconds an
InnoDBtransaction may wait for a row lock before giving up. The default value is 50 seconds. A transaction that tries to access a row that is locked by anotherInnoDBtransaction will hang for at most this many seconds before issuing the following error:ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
When a lock wait timeout occurs, the current statement is not executed. The current transaction is not rolled back. (Until MySQL 5.0.13
InnoDBrolled back the entire transaction if a lock wait timeout happened. You can restore this behavior by starting the server with the--innodb_rollback_on_timeoutoption, available as of MySQL 5.0.32. See also Section 13.2.12, “InnoDBError Handling”.)innodb_lock_wait_timeoutapplies toInnoDBrow locks only. A MySQL table lock does not happen insideInnoDBand this timeout does not apply to waits for table locks.InnoDBdoes detect transaction deadlocks in its own lock table immediately and rolls back one transaction. The lock wait timeout value does not apply to such a wait.innodb_locks_unsafe_for_binlogThis variable affects how
InnoDBuses gap locking for searches and index scans. Normally,InnoDBuses an algorithm called next-key locking that combines index-row locking with gap locking.InnoDBperforms row-level locking in such a way that when it searches or scans a table index, it sets shared or exclusive locks on the index records it encounters. Thus, the row-level locks are actually index-record locks. In addition, a next-key lock on an index record also affects the “gap” before that index record. That is, a next-key lock is an index-record lock plus a gap lock on the gap preceding the index record. If one session has a shared or exclusive lock on recordRin an index, another session cannot insert a new index record in the gap immediately beforeRin the index order. See Section 13.2.8.4, “InnoDBRecord, Gap, and Next-Key Locks”.By default, the value of
innodb_locks_unsafe_for_binlogis 0 (disabled), which means that gap locking is enabled:InnoDBuses next-key locks for searches and index scans. To enable the variable, set it to 1. This causes gap locking to be disabled:InnoDBuses only index-record locks for searches and index scans.Enabling
innodb_locks_unsafe_for_binlogdoes not disable the use of gap locking for foreign-key constraint checking or duplicate-key checking.The effect of enabling
innodb_locks_unsafe_for_binlogis similar to but not identical to setting the transaction isolation level toREAD COMMITTED:Enabling
innodb_locks_unsafe_for_binlogis a global setting and affects all sessions, whereas the isolation level can be set globally for all sessions, or individually per sesssion.innodb_locks_unsafe_for_binlogcan be set only at server startup, whereas the isolation level can be set at startup or changed at runtime.
READ COMMITTEDtherefore offers finer and more flexible control thaninnodb_locks_unsafe_for_binlog. For additional details about the effect of isolation level on gap locking, see Section 12.4.6, “SET TRANSACTIONSyntax”.Enabling
innodb_locks_unsafe_for_binlogmay cause phantom problems because other sessions can insert new rows into the gaps when gap locking is disabled. Suppose that there is an index on theidcolumn of thechildtable and that you want to read and lock all rows from the table having an identifier value larger than 100, with the intention of updating some column in the selected rows later:SELECT * FROM child WHERE id > 100 FOR UPDATE;
The query scans the index starting from the first record where
idis greater than 100. If the locks set on the index records in that range do not lock out inserts made in the gaps, another session can insert a new row into the table. Consequently, if you were to execute the sameSELECTagain within the same transaction, you would see a new row in the result set returned by the query. This also means that if new items are added to the database,InnoDBdoes not guarantee serializability. Therefore, ifinnodb_locks_unsafe_for_binlogis enabled,InnoDBguarantees at most an isolation level ofREAD COMMITTED. (Conflict serializability is still guaranteed.) For additional information about phantoms, see Section 13.2.8.5, “Avoiding the Phantom Problem Using Next-Key Locking”.Starting from MySQL 5.0.2, enabling
innodb_locks_unsafe_for_binloghas an additional effect. ForUPDATEorDELETEstatements,InnoDBholds locks only for rows that it updates or deletes. Record locks for nonmatching rows are released after MySQL has evaluated theWHEREcondition. This greatly reduces the probability of deadlocks, but they can still happen. Note that enabling this variable still does not allow operations such asUPDATEto overtake other similar operations (such as anotherUPDATE) even when they affect different rows.Consider the following example, beginning with this table:
CREATE TABLE t (a INT NOT NULL, b INT) ENGINE = InnoDB; INSERT INTO t VALUES (1,2),(2,3),(3,2),(4,3),(5,2); COMMIT;
In this case, table has no indexes, so searches and index scans use the hidden clustered index for record locking (see Section 13.2.10.1, “Clustered and Secondary Indexes”).
Suppose that one client performs an
UPDATEusing these statements:SET autocommit = 0; UPDATE t SET b = 5 WHERE b = 3;
Suppose also that a second client performs an
UPDATEby executing these statements following those of the first client:SET autocommit = 0; UPDATE t SET b = 4 WHERE b = 2;
As
InnoDBexecutes eachUPDATE, it first acquires an exclusive lock for each row, and then determines whether to modify it. IfInnoDBdoes not modify the row andinnodb_locks_unsafe_for_binlogis enabled, it releases the lock. Otherwise,InnoDBretains the lock until the end of the transaction. This affects transaction processing as follows.If
innodb_locks_unsafe_for_binlogis disabled, the firstUPDATEacquires x-locks and does not release any of them:x-lock(1,2); retain x-lock x-lock(2,3); update(2,3) to (2,5); retain x-lock x-lock(3,2); retain x-lock x-lock(4,3); update(4,3) to (4,5); retain x-lock x-lock(5,2); retain x-lock
The second
UPDATEblocks as soon as it tries to acquire any locks (because first update has retained locks on all rows), and does not proceed until the firstUPDATEcommits or rolls back:x-lock(1,2); block and wait for first UPDATE to commit or roll back
If
innodb_locks_unsafe_for_binlogis enabled, the firstUPDATEacquires x-locks and releases those for rows that it does not modify:x-lock(1,2); unlock(1,2) x-lock(2,3); update(2,3) to (2,5); retain x-lock x-lock(3,2); unlock(3,2) x-lock(4,3); update(4,3) to (4,5); retain x-lock x-lock(5,2); unlock(5,2)
The second
UPDATEproceeds part way before it blocks. It begins acquiring x-locks, and blocks when it tries to acquire one for a row still locked by firstUPDATE. The secondUPDATEdoes not proceed until the firstUPDATEcommits or rolls back:x-lock(1,2); update(1,2) to (1,4); retain x-lock x-lock(2,3); block and wait for first UPDATE to commit or roll back
In this case, the second
UPDATEmust wait for a commit or rollback of the firstUPDATE, even though it affects different rows. The firstUPDATEhas an exclusive lock on row (2,3) that it has not released. As the secondUPDATEscans rows, it tries to acquire an exclusive lock for that same row, which it cannot have.This variable is unused, and is deprecated as of MySQL 5.0.24. It will be removed in MySQL 5.1
Whether to log
InnoDBarchive files. This variable is present for historical reasons, but is unused. Recovery from a backup is done by MySQL using its own log files, so there is no need to archiveInnoDBlog files. The default for this variable is 0.The size in bytes of the buffer that
InnoDBuses to write to the log files on disk. The default value is 1MB. Sensible values range from 1MB to 8MB. A large log buffer allows large transactions to run without a need to write the log to disk before the transactions commit. Thus, if you have big transactions, making the log buffer larger saves disk I/O.The size in bytes of each log file in a log group. The combined size of log files must be less than 4GB. The default value is 5MB. Sensible values range from 1MB to 1/
N-th of the size of the buffer pool, whereNis the number of log files in the group. The larger the value, the less checkpoint flush activity is needed in the buffer pool, saving disk I/O. But larger log files also mean that recovery is slower in case of a crash.The number of log files in the log group.
InnoDBwrites to the files in a circular fashion. The default (and recommended) value is 2.The directory path to the
InnoDBlog files. If you do not specify anyInnoDBlog variables, the default is to create two 5MB files namesib_logfile0andib_logfile1in the MySQL data directory.This is an integer in the range from 0 to 100. The default value is 90. The main thread in
InnoDBtries to write pages from the buffer pool so that the percentage of dirty (not yet written) pages will not exceed this value.This variable controls how to delay
INSERT,UPDATE, andDELETEoperations when purge operations are lagging (see Section 13.2.9, “InnoDBMulti-Versioning”). The default value 0 (no delays).The
InnoDBtransaction system maintains a list of transactions that have delete-marked index records byUPDATEorDELETEoperations. Let the length of this list bepurge_lag. Whenpurge_lagexceedsinnodb_max_purge_lag, eachINSERT,UPDATE, andDELETEoperation is delayed by ((purge_lag/innodb_max_purge_lag)×10)–5 milliseconds. The delay is computed in the beginning of a purge batch, every ten seconds. The operations are not delayed if purge cannot run because of an old consistent read view that could see the rows to be purged.A typical setting for a problematic workload might be 1 million, assuming that transactions are small, only 100 bytes in size, and it is allowable to have 100MB of unpurged
InnoDBtable rows.The number of identical copies of log groups to keep for the database. This should be set to 1.
This variable is relevant only if you use multiple tablespaces in
InnoDB. It specifies the maximum number of.ibdfiles thatInnoDBcan keep open at one time. The minimum value is 10. The default value is 300.The file descriptors used for
.ibdfiles are forInnoDBonly. They are independent of those specified by the--open-files-limitserver option, and do not affect the operation of the table cache.In MySQL 5.0.13 and up,
InnoDBrolls back only the last statement on a transaction timeout by default. If--innodb_rollback_on_timeoutis specified, a transaction timeout causesInnoDBto abort and roll back the entire transaction (the same behavior as before MySQL 5.0.13). This variable was added in MySQL 5.0.32.innodb_safe_binlogIf this option is given, then after a crash recovery by
InnoDB, mysqld truncates the binary log after the last not-rolled-back transaction in the log. The option also causesInnoDBto print an error if the binary log is smaller or shorter than it should be. See Section 5.2.3, “The Binary Log”. This variable was removed in MySQL 5.0.3, having been made obsolete by the introduction of XA transaction support. You should setinnodb_support_xatoONor 1 to ensure consistency. Seeinnodb_support_xa.When the variable is enabled (the default),
InnoDBsupport for two-phase commit in XA transactions is enabled, which causes an extra disk flush for transaction preparation.If you do not wish to use XA transactions, you can disable this variable to reduce the number of disk flushes and get better
InnoDBperformance.Having
innodb_support_xaenabled on a replication master — or on any MySQL server where binary logging is in use — ensures that the binary log does not get out of sync compared to the table data.This variable was added in MySQL 5.0.3.
The number of times a thread waits for an
InnoDBmutex to be freed before the thread is suspended. The default value is 20. This variable was added in MySQL 5.0.3.If
autocommit = 0,InnoDBhonorsLOCK TABLES; MySQL does not return fromLOCK TABLES ... WRITEuntil all other threads have released all their locks to the table. The default value ofinnodb_table_locksis 1, which means thatLOCK TABLEScauses InnoDB to lock a table internally ifautocommit = 0.InnoDBtries to keep the number of operating system threads concurrently insideInnoDBless than or equal to the limit given by this variable. Once the number of threads reaches this limit, additional threads are placed into a wait state within a FIFO queue for execution. Threads waiting for locks are not counted in the number of concurrently executing threads.The correct value for this variable is dependent on environment and workload. You will need to try a range of different values to determine what value works for your applications.
The range of this variable is 0 to 1000. A value of 20 or higher is interpreted as infinite concurrency before MySQL 5.0.19. From 5.0.19 on, you can disable thread concurrency checking by setting the value to 0. Disabling thread concurrency checking allows InnoDB to create as many threads as it needs.
The default value has changed several times: 8 before MySQL 5.0.8, 20 (infinite) from 5.0.8 through 5.0.18, 0 (infinite) from 5.0.19 to 5.0.20, and 8 (finite) from 5.0.21 on.
How long
InnoDBthreads sleep before joining theInnoDBqueue, in microseconds. The default value is 10,000. A value of 0 disables sleep. This variable was added in MySQL 5.0.3.innodb_use_legacy_cardinality_algorithmInnoDBuses random numbers to generate dives into indexes for calculating index cardinality. However, under certain conditions, the algorithm does not generate random numbers, soANALYZE TABLEsometimes does not update cardinality estimates properly. An alternative algorithm was introduced in MySQL 5.0.82 with better randomization properties, and theinnodb_use_legacy_cardinality_algorithm, system variable which algorithm to use. The default value of the variable is 1 (ON), to use the original algorithm for compatibility with existing applications. The variable can be set to 0 (OFF) to use the new algorithm with improved randomness.If the value of this variable is greater than 0, the MySQL server synchronizes its binary log to disk (using
fdatasync()) after everysync_binlogwrites to the binary log. There is one write to the binary log per statement if autocommit is enabled, and one write per transaction otherwise. The default value ofsync_binlogis 0, which does no synchronizing to disk. A value of 1 is the safest choice, because in the event of a crash you lose at most one statement or transaction from the binary log. However, it is also the slowest choice (unless the disk has a battery-backed cache, which makes synchronization very fast).
To create an InnoDB table, specify an
ENGINE = InnoDB option in the
CREATE TABLE statement:
CREATE TABLE customers (a INT, b CHAR (20), INDEX (a)) ENGINE=InnoDB;
The older term TYPE is supported as a synonym
for ENGINE for backward compatibility, but
ENGINE is the preferred term and
TYPE is deprecated.
The statement creates a table and an index on column
a in the InnoDB tablespace
that consists of the data files that you specified in
my.cnf. In addition, MySQL creates a file
customers.frm in the
test directory under the MySQL database
directory. Internally, InnoDB adds an entry for
the table to its own data dictionary. The entry includes the
database name. For example, if test is the
database in which the customers table is
created, the entry is for 'test/customers'.
This means you can create a table of the same name
customers in some other database, and the table
names do not collide inside InnoDB.
You can query the amount of free space in the
InnoDB tablespace by issuing a
SHOW TABLE STATUS statement for any
InnoDB table. The amount of free space in the
tablespace appears in the Comment section in
the output of SHOW TABLE STATUS.
For example:
SHOW TABLE STATUS FROM test LIKE 'customers'
The statistics SHOW displays for
InnoDB tables are only approximate. They are
used in SQL optimization. Table and index reserved sizes in bytes
are accurate, though.
By default, each client that connects to the MySQL server begins
with autocommit mode enabled, which automatically commits every
SQL statement as you execute it. To use multiple-statement
transactions, you can switch autocommit off with the SQL
statement SET autocommit = 0 and end each
transaction with either COMMIT or
ROLLBACK. If
you want to leave autocommit on, you can begin your transactions
within START
TRANSACTION and end them with
COMMIT or
ROLLBACK. The
following example shows two transactions. The first is
committed; the second is rolled back.
shell>mysql testmysql>CREATE TABLE customer (a INT, b CHAR (20), INDEX (a))->ENGINE=InnoDB;Query OK, 0 rows affected (0.00 sec) mysql>START TRANSACTION;Query OK, 0 rows affected (0.00 sec) mysql>INSERT INTO customer VALUES (10, 'Heikki');Query OK, 1 row affected (0.00 sec) mysql>COMMIT;Query OK, 0 rows affected (0.00 sec) mysql>SET autocommit=0;Query OK, 0 rows affected (0.00 sec) mysql>INSERT INTO customer VALUES (15, 'John');Query OK, 1 row affected (0.00 sec) mysql>ROLLBACK;Query OK, 0 rows affected (0.00 sec) mysql>SELECT * FROM customer;+------+--------+ | a | b | +------+--------+ | 10 | Heikki | +------+--------+ 1 row in set (0.00 sec) mysql>
In APIs such as PHP, Perl DBI, JDBC, ODBC, or the standard C
call interface of MySQL, you can send transaction control
statements such as COMMIT to the
MySQL server as strings just like any other SQL statements such
as SELECT or
INSERT. Some APIs also offer
separate special transaction commit and rollback functions or
methods.
To convert a non-InnoDB table to use
InnoDB use ALTER
TABLE:
ALTER TABLE t1 ENGINE=InnoDB;
Important
Do not convert MySQL system tables in the
mysql database (such as
user or host) to the
InnoDB type. This is an unsupported
operation. The system tables must always be of the
MyISAM type.
InnoDB does not have a special optimization
for separate index creation the way the
MyISAM storage engine does. Therefore, it
does not pay to export and import the table and create indexes
afterward. The fastest way to alter a table to
InnoDB is to do the inserts directly to an
InnoDB table. That is, use ALTER
TABLE ... ENGINE=INNODB, or create an empty
InnoDB table with identical definitions and
insert the rows with INSERT INTO ... SELECT * FROM
....
If you have UNIQUE constraints on secondary
keys, you can speed up a table import by turning off the
uniqueness checks temporarily during the import operation:
SET unique_checks=0;
... import operation ...
SET unique_checks=1;
For big tables, this saves a lot of disk I/O because
InnoDB can then use its insert buffer to
write secondary index records as a batch. Be certain that the
data contains no duplicate keys.
unique_checks allows but does
not require storage engines to ignore duplicate keys.
To get better control over the insertion process, it might be good to insert big tables in pieces:
INSERT INTO newtable SELECT * FROM oldtable WHERE yourkey > something AND yourkey <= somethingelse;
After all records have been inserted, you can rename the tables.
During the conversion of big tables, you should increase the
size of the InnoDB buffer pool to reduce disk
I/O. Do not use more than 80% of the physical memory, though.
You can also increase the sizes of the InnoDB
log files.
Make sure that you do not fill up the tablespace:
InnoDB tables require a lot more disk space
than MyISAM tables. If an
ALTER TABLE operation runs out of
space, it starts a rollback, and that can take hours if it is
disk-bound. For inserts, InnoDB uses the
insert buffer to merge secondary index records to indexes in
batches. That saves a lot of disk I/O. For rollback, no such
mechanism is used, and the rollback can take 30 times longer
than the insertion.
In the case of a runaway rollback, if you do not have valuable
data in your database, it may be advisable to kill the database
process rather than wait for millions of disk I/O operations to
complete. For the complete procedure, see
Section 13.2.6.2, “Forcing InnoDB Recovery”.
If you want all your (nonsystem) tables to be created as
InnoDB tables, add the line
default-storage-engine=innodb to the
[mysqld] section of your server option file.
If you specify an AUTO_INCREMENT column for
an InnoDB table, the table handle in the
InnoDB data dictionary contains a special
counter called the auto-increment counter that is used in
assigning new values for the column. This counter is stored only
in main memory, not on disk.
InnoDB uses the following algorithm to
initialize the auto-increment counter for a table
t that contains an
AUTO_INCREMENT column named
ai_col: After a server startup, for the first
insert into a table t,
InnoDB executes the equivalent of this
statement:
SELECT MAX(ai_col) FROM t FOR UPDATE;
InnoDB increments by one the value retrieved
by the statement and assigns it to the column and to the
auto-increment counter for the table. If the table is empty,
InnoDB uses the value 1.
If a user invokes a SHOW TABLE
STATUS statement that displays output for the table
t and the auto-increment counter has not been
initialized, InnoDB initializes but does not
increment the value and stores it for use by later inserts. This
initialization uses a normal exclusive-locking read on the table
and the lock lasts to the end of the transaction.
InnoDB follows the same procedure for
initializing the auto-increment counter for a freshly created
table.
After the auto-increment counter has been initialized, if a user
does not explicitly specify a value for an
AUTO_INCREMENT column,
InnoDB increments the counter by one and
assigns the new value to the column. If the user inserts a row
that explicitly specifies the column value, and the value is
bigger than the current counter value, the counter is set to the
specified column value.
When accessing the auto-increment counter,
InnoDB uses a special table-level
AUTO-INC lock that it keeps to the end of the
current SQL statement, not to the end of the transaction. The
special lock release strategy was introduced to improve
concurrency for inserts into a table containing an
AUTO_INCREMENT column. Nevertheless, two
transactions cannot have the AUTO-INC lock on
the same table simultaneously, which can have a performance
impact if the AUTO-INC lock is held for a
long time. That might be the case for a statement such as
INSERT INTO t1 ... SELECT ... FROM t2 that
inserts all rows from one table into another.
InnoDB uses the in-memory auto-increment
counter as long as the server runs. When the server is stopped
and restarted, InnoDB reinitializes the
counter for each table for the first
INSERT to the table, as described
earlier.
You may see gaps in the sequence of values assigned to the
AUTO_INCREMENT column if you roll back
transactions that have generated numbers using the counter.
If a user specifies NULL or
0 for the AUTO_INCREMENT
column in an INSERT,
InnoDB treats the row as if the value had not
been specified and generates a new value for it.
The behavior of the auto-increment mechanism is not defined if a user assigns a negative value to the column or if the value becomes bigger than the maximum integer that can be stored in the specified integer type.
An AUTO_INCREMENT column must appear as the
first column in an index on an InnoDB table.
Beginning with MySQL 5.0.3, InnoDB supports
the AUTO_INCREMENT =
table option in
NCREATE TABLE and
ALTER TABLE statements, to set
the initial counter value or alter the current counter value.
The effect of this option is canceled by a server restart, for
reasons discussed earlier in this section.
InnoDB supports foreign key constraints. The
syntax for a foreign key constraint definition in
InnoDB looks like this:
[CONSTRAINT [symbol]] FOREIGN KEY [index_name] (index_col_name, ...) REFERENCEStbl_name(index_col_name,...) [ON DELETEreference_option] [ON UPDATEreference_option]reference_option: RESTRICT | CASCADE | SET NULL | NO ACTION
index_name represents a foreign key
ID. If given, this is ignored if an index for the foreign key is
defined explicitly. Otherwise, if InnoDB
creates an index for the foreign key, it uses
index_name for the index name.
Foreign keys definitions are subject to the following conditions:
Both tables must be
InnoDBtables and they must not beTEMPORARYtables.Corresponding columns in the foreign key and the referenced key must have similar internal data types inside
InnoDBso that they can be compared without a type conversion. The size and sign of integer types must be the same. The length of string types need not be the same. For nonbinary (character) string columns, the character set and collation must be the same.InnoDBrequires indexes on foreign keys and referenced keys so that foreign key checks can be fast and not require a table scan. In the referencing table, there must be an index where the foreign key columns are listed as the first columns in the same order. Such an index is created on the referencing table automatically if it does not exist. (This is in contrast to some older versions, in which indexes had to be created explicitly or the creation of foreign key constraints would fail.)index_name, if given, is used as described previously.InnoDBallows a foreign key to reference any index column or group of columns. However, in the referenced table, there must be an index where the referenced columns are listed as the first columns in the same order.Index prefixes on foreign key columns are not supported. One consequence of this is that
BLOBandTEXTcolumns cannot be included in a foreign key because indexes on those columns must always include a prefix length.If the
CONSTRAINTclause is given, thesymbolsymbolvalue must be unique in the database. If the clause is not given,InnoDBcreates the name automatically.
InnoDB rejects any
INSERT or
UPDATE operation that attempts to
create a foreign key value in a child table if there is no a
matching candidate key value in the parent table. The action
InnoDB takes for any
UPDATE or
DELETE operation that attempts to
update or delete a candidate key value in the parent table that
has some matching rows in the child table is dependent on the
referential action specified using
ON UPDATE and ON DELETE
subclauses of the FOREIGN KEY clause. When
the user attempts to delete or update a row from a parent table,
and there are one or more matching rows in the child table,
InnoDB supports five options regarding the
action to be taken. If ON DELETE or
ON UPDATE are not specified, the default
action is RESTRICT.
CASCADE: Delete or update the row from the parent table and automatically delete or update the matching rows in the child table. BothON DELETE CASCADEandON UPDATE CASCADEare supported. Between two tables, you should not define severalON UPDATE CASCADEclauses that act on the same column in the parent table or in the child table.Note
Currently, cascaded foreign key actions to not activate triggers.
SET NULL: Delete or update the row from the parent table and set the foreign key column or columns in the child table toNULL. This is valid only if the foreign key columns do not have theNOT NULLqualifier specified. BothON DELETE SET NULLandON UPDATE SET NULLclauses are supported.If you specify a
SET NULLaction, make sure that you have not declared the columns in the child table asNOT NULL.NO ACTION: In standard SQL,NO ACTIONmeans no action in the sense that an attempt to delete or update a primary key value is not allowed to proceed if there is a related foreign key value in the referenced table.InnoDBrejects the delete or update operation for the parent table.RESTRICT: Rejects the delete or update operation for the parent table. SpecifyingRESTRICT(orNO ACTION) is the same as omitting theON DELETEorON UPDATEclause. (Some database systems have deferred checks, andNO ACTIONis a deferred check. In MySQL, foreign key constraints are checked immediately, soNO ACTIONis the same asRESTRICT.)SET DEFAULT: This action is recognized by the parser, butInnoDBrejects table definitions containingON DELETE SET DEFAULTorON UPDATE SET DEFAULTclauses.
InnoDB supports foreign key references within
a table. In these cases, “child table records”
really refers to dependent records within the same table.
Here is a simple example that relates parent
and child tables through a single-column
foreign key:
CREATE TABLE parent (id INT NOT NULL,
PRIMARY KEY (id)
) ENGINE=INNODB;
CREATE TABLE child (id INT, parent_id INT,
INDEX par_ind (parent_id),
FOREIGN KEY (parent_id) REFERENCES parent(id)
ON DELETE CASCADE
) ENGINE=INNODB;
A more complex example in which a
product_order table has foreign keys for two
other tables. One foreign key references a two-column index in
the product table. The other references a
single-column index in the customer table:
CREATE TABLE product (category INT NOT NULL, id INT NOT NULL,
price DECIMAL,
PRIMARY KEY(category, id)) ENGINE=INNODB;
CREATE TABLE customer (id INT NOT NULL,
PRIMARY KEY (id)) ENGINE=INNODB;
CREATE TABLE product_order (no INT NOT NULL AUTO_INCREMENT,
product_category INT NOT NULL,
product_id INT NOT NULL,
customer_id INT NOT NULL,
PRIMARY KEY(no),
INDEX (product_category, product_id),
FOREIGN KEY (product_category, product_id)
REFERENCES product(category, id)
ON UPDATE CASCADE ON DELETE RESTRICT,
INDEX (customer_id),
FOREIGN KEY (customer_id)
REFERENCES customer(id)) ENGINE=INNODB;
InnoDB allows you to add a new foreign key
constraint to a table by using ALTER
TABLE:
ALTER TABLEtbl_nameADD [CONSTRAINT [symbol]] FOREIGN KEY [index_name] (index_col_name, ...) REFERENCEStbl_name(index_col_name,...) [ON DELETEreference_option] [ON UPDATEreference_option]
The foreign key can be self referential (referring to the same
table). When you add a foreign key constraint to a table using
ALTER TABLE, remember
to create the required indexes first.
InnoDB supports the use of
ALTER TABLE to drop foreign keys:
ALTER TABLEtbl_nameDROP FOREIGN KEYfk_symbol;
If the FOREIGN KEY clause included a
CONSTRAINT name when you created the foreign
key, you can refer to that name to drop the foreign key.
Otherwise, the fk_symbol value is
internally generated by InnoDB when the
foreign key is created. To find out the symbol value when you
want to drop a foreign key, use the SHOW
CREATE TABLE statement. For example:
mysql>SHOW CREATE TABLE ibtest11c\G*************************** 1. row *************************** Table: ibtest11c Create Table: CREATE TABLE `ibtest11c` ( `A` int(11) NOT NULL auto_increment, `D` int(11) NOT NULL default '0', `B` varchar(200) NOT NULL default '', `C` varchar(175) default NULL, PRIMARY KEY (`A`,`D`,`B`), KEY `B` (`B`,`C`), KEY `C` (`C`), CONSTRAINT `0_38775` FOREIGN KEY (`A`, `D`) REFERENCES `ibtest11a` (`A`, `D`) ON DELETE CASCADE ON UPDATE CASCADE, CONSTRAINT `0_38776` FOREIGN KEY (`B`, `C`) REFERENCES `ibtest11a` (`B`, `C`) ON DELETE CASCADE ON UPDATE CASCADE ) ENGINE=INNODB CHARSET=latin1 1 row in set (0.01 sec) mysql>ALTER TABLE ibtest11c DROP FOREIGN KEY `0_38775`;
You cannot add a foreign key and drop a foreign key in separate
clauses of a single ALTER TABLE
statement. Separate statements are required.
If ALTER TABLE for an
InnoDB table results in changes to column
values (for example, because a column is truncated),
InnoDB's FOREIGN KEY
constraint checks do not notice possible violations caused by
changing the values.
The InnoDB parser allows table and column
identifiers in a FOREIGN KEY ... REFERENCES
... clause to be quoted within backticks.
(Alternatively, double quotes can be used if the
ANSI_QUOTES SQL mode is
enabled.) The InnoDB parser also takes into
account the setting of the
lower_case_table_names system
variable.
InnoDB returns a table's foreign key
definitions as part of the output of the
SHOW CREATE TABLE statement:
SHOW CREATE TABLE tbl_name;
mysqldump also produces correct definitions of tables in the dump file, and does not forget about the foreign keys.
You can also display the foreign key constraints for a table like this:
SHOW TABLE STATUS FROMdb_nameLIKE 'tbl_name';
The foreign key constraints are listed in the
Comment column of the output.
When performing foreign key checks, InnoDB
sets shared row-level locks on child or parent records it has to
look at. InnoDB checks foreign key
constraints immediately; the check is not deferred to
transaction commit.
To make it easier to reload dump files for tables that have
foreign key relationships, mysqldump
automatically includes a statement in the dump output to set
foreign_key_checks to 0. This
avoids problems with tables having to be reloaded in a
particular order when the dump is reloaded. It is also possible
to set this variable manually:
mysql>SET foreign_key_checks = 0;mysql>SOURCEmysql>dump_file_name;SET foreign_key_checks = 1;
This allows you to import the tables in any order if the dump
file contains tables that are not correctly ordered for foreign
keys. It also speeds up the import operation. Setting
foreign_key_checks to 0 can
also be useful for ignoring foreign key constraints during
LOAD DATA and
ALTER TABLE operations. However,
even if foreign_key_checks = 0,
InnoDB does not allow the creation of a foreign key constraint
where a column references a nonmatching column type. Also, if an
InnoDB table has foreign key constraints,
ALTER TABLE cannot be used to
change the table to use another storage engine. To alter the
storage engine, you must drop any foreign key constraints first.
InnoDB does not allow you to drop a table
that is referenced by a FOREIGN KEY
constraint, unless you do SET foreign_key_checks =
0. When you drop a table, the constraints that were
defined in its create statement are also dropped.
If you re-create a table that was dropped, it must have a definition that conforms to the foreign key constraints referencing it. It must have the right column names and types, and it must have indexes on the referenced keys, as stated earlier. If these are not satisfied, MySQL returns error number 1005 and refers to error 150 in the error message.
If MySQL reports an error number 1005 from a
CREATE TABLE statement, and the
error message refers to error 150, table creation failed because
a foreign key constraint was not correctly formed. Similarly, if
an ALTER TABLE fails and it
refers to error 150, that means a foreign key definition would
be incorrectly formed for the altered table. You can use
SHOW ENGINE INNODB
STATUS to display a detailed explanation of the most
recent InnoDB foreign key error in the
server.
Important
For users familiar with the ANSI/ISO SQL Standard, please note
that no storage engine, including InnoDB,
recognizes or enforces the MATCH clause
used in referential-integrity constraint definitions. Use of
an explicit MATCH clause will not have the
specified effect, and also causes ON DELETE
and ON UPDATE clauses to be ignored. For
these reasons, specifying MATCH should be
avoided.
The MATCH clause in the SQL standard
controls how NULL values in a composite
(multiple-column) foreign key are handled when comparing to a
primary key. InnoDB essentially implements
the semantics defined by MATCH SIMPLE,
which allow a foreign key to be all or partially
NULL. In that case, the (child table) row
containing such a foreign key is allowed to be inserted, and
does not match any row in the referenced (parent) table. It is
possible to implement other semantics using triggers.
Additionally, MySQL and InnoDB require that
the referenced columns be indexed for performance. However,
the system does not enforce a requirement that the referenced
columns be UNIQUE or be declared
NOT NULL. The handling of foreign key
references to nonunique keys or keys that contain
NULL values is not well defined for
operations such as UPDATE or
DELETE CASCADE. You are advised to use
foreign keys that reference only UNIQUE and
NOT NULL keys.
Furthermore, InnoDB does not recognize or
support “inline REFERENCES
specifications” (as defined in the SQL standard) where
the references are defined as part of the column
specification. InnoDB accepts
REFERENCES clauses only when specified as
part of a separate FOREIGN KEY
specification. For other storage engines, MySQL Server parses
and ignores foreign key specifications.
Deviation from SQL standards:
If there are several rows in the parent table that have the same
referenced key value, InnoDB acts in foreign
key checks as if the other parent rows with the same key value
do not exist. For example, if you have defined a
RESTRICT type constraint, and there is a
child row with several parent rows, InnoDB
does not allow the deletion of any of those parent rows.
InnoDB performs cascading operations through
a depth-first algorithm, based on records in the indexes
corresponding to the foreign key constraints.
Deviation from SQL standards: A
FOREIGN KEY constraint that references a
non-UNIQUE key is not standard SQL. It is an
InnoDB extension to standard SQL.
Deviation from SQL standards:
If ON UPDATE CASCADE or ON UPDATE
SET NULL recurses to update the same
table it has previously updated during the cascade,
it acts like RESTRICT. This means that you
cannot use self-referential ON UPDATE CASCADE
or ON UPDATE SET NULL operations. This is to
prevent infinite loops resulting from cascaded updates. A
self-referential ON DELETE SET NULL, on the
other hand, is possible, as is a self-referential ON
DELETE CASCADE. Cascading operations may not be nested
more than 15 levels deep.
Deviation from SQL standards:
Like MySQL in general, in an SQL statement that inserts,
deletes, or updates many rows, InnoDB checks
UNIQUE and FOREIGN KEY
constraints row-by-row. According to the SQL standard, the
default behavior should be deferred checking. That is,
constraints are only checked after the entire SQL
statement has been processed. Until
InnoDB implements deferred constraint
checking, some things will be impossible, such as deleting a
record that refers to itself via a foreign key.
MySQL replication works for InnoDB tables as
it does for MyISAM tables. It is also
possible to use replication in a way where the storage engine on
the slave is not the same as the original storage engine on the
master. For example, you can replicate modifications to an
InnoDB table on the master to a
MyISAM table on the slave.
To set up a new slave for a master, you have to make a copy of
the InnoDB tablespace and the log files, as
well as the .frm files of the
InnoDB tables, and move the copies to the
slave. If the
innodb_file_per_table variable
is enabled, you must also copy the .ibd
files as well. For the proper procedure to do this, see
Section 13.2.6, “Backing Up and Recovering an InnoDB Database”.
If you can shut down the master or an existing slave, you can
take a cold backup of the InnoDB tablespace
and log files and use that to set up a slave. To make a new
slave without taking down any server you can also use the
commercial
InnoDB
Hot Backup tool.
You cannot set up replication for InnoDB
using the LOAD TABLE FROM MASTER statement,
which works only for MyISAM tables. There are
two possible workarounds:
Dump the table on the master and import the dump file into the slave.
Use
ALTER TABLEon the master before setting up replication withtbl_nameENGINE=MyISAMLOAD TABLE, and then usetbl_nameFROM MASTERALTER TABLEto convert the master table back toInnoDBafterward. However, this should not be done for tables that have foreign key definitions because the definitions will be lost.
Transactions that fail on the master do not affect replication
at all. MySQL replication is based on the binary log where MySQL
writes SQL statements that modify data. A transaction that fails
(for example, because of a foreign key violation, or because it
is rolled back) is not written to the binary log, so it is not
sent to slaves. See Section 12.4.1, “START TRANSACTION,
COMMIT, and
ROLLBACK Syntax”.
Replication and CASCADE.
Cascading actions for InnoDB tables on the
master are replicated on the slave only
if the tables sharing the foreign key relation use
InnoDB on both the master and slave. For
example, suppose you have started replication, and then create
two tables on the master using the following
CREATE TABLE statements:
CREATE TABLE fc1 (
i INT PRIMARY KEY,
j INT
) ENGINE = InnoDB;
CREATE TABLE fc2 (
m INT PRIMARY KEY,
n INT,
FOREIGN KEY ni (n) REFERENCES fc1 (i)
ON DELETE CASCADE
) ENGINE = InnoDB;
Suppose that the slave does not have InnoDB
support enabled. If this is the case, then the tables on the
slave are created, but they use the MyISAM
storage engine, and the FOREIGN KEY option
is ignored. Now we insert some rows into the tables on the
master:
master>INSERT INTO fc1 VALUES (1, 1), (2, 2);Query OK, 2 rows affected (0.09 sec) Records: 2 Duplicates: 0 Warnings: 0 master>INSERT INTO fc2 VALUES (1, 1), (2, 2), (3, 1);Query OK, 3 rows affected (0.19 sec) Records: 3 Duplicates: 0 Warnings: 0
At this point, on both the master and the slave, table
fc1 contains 2 rows, and table
fc2 contains 3 rows, as shown here:
master>SELECT * FROM fc1;+---+------+ | i | j | +---+------+ | 1 | 1 | | 2 | 2 | +---+------+ 2 rows in set (0.00 sec) master>SELECT * FROM fc2;+---+------+ | m | n | +---+------+ | 1 | 1 | | 2 | 2 | | 3 | 1 | +---+------+ 3 rows in set (0.00 sec) slave>SELECT * FROM fc1;+---+------+ | i | j | +---+------+ | 1 | 1 | | 2 | 2 | +---+------+ 2 rows in set (0.00 sec) slave>SELECT * FROM fc2;+---+------+ | m | n | +---+------+ | 1 | 1 | | 2 | 2 | | 3 | 1 | +---+------+ 3 rows in set (0.00 sec)
Now suppose that you perform the following
DELETE statement on the master:
master> DELETE FROM fc1 WHERE i=1;
Query OK, 1 row affected (0.09 sec)
Due to the cascade, table fc2 on the master
now contains only 1 row:
master> SELECT * FROM fc2;
+---+---+
| m | n |
+---+---+
| 2 | 2 |
+---+---+
1 row in set (0.00 sec)
However, the cascade does not propagate on the slave because
on the slave the DELETE for
fc1 deletes no rows from
fc2. The slave's copy of
fc2 still contains all of the rows that
were originally inserted:
slave> SELECT * FROM fc2;
+---+---+
| m | n |
+---+---+
| 1 | 1 |
| 3 | 1 |
| 2 | 2 |
+---+---+
3 rows in set (0.00 sec)
This difference is due to the fact that the cascading deletes
are handled internally by the InnoDB
storage engine, which means that none of the changes are
logged.
This section describes what you can do when your
InnoDB tablespace runs out of room or when you
want to change the size of the log files.
The easiest way to increase the size of the
InnoDB tablespace is to configure it from the
beginning to be auto-extending. Specify the
autoextend attribute for the last data file in
the tablespace definition. Then InnoDB
increases the size of that file automatically in 8MB increments
when it runs out of space. The increment size can be changed by
setting the value of the
innodb_autoextend_increment
system variable, which is measured in MB.
Alternatively, you can increase the size of your tablespace by
adding another data file. To do this, you have to shut down the
MySQL server, change the tablespace configuration to add a new
data file to the end of
innodb_data_file_path, and start
the server again.
If your last data file was defined with the keyword
autoextend, the procedure for reconfiguring the
tablespace must take into account the size to which the last data
file has grown. Obtain the size of the data file, round it down to
the closest multiple of 1024 × 1024 bytes (= 1MB), and
specify the rounded size explicitly in
innodb_data_file_path. Then you
can add another data file. Remember that only the last data file
in the innodb_data_file_path can
be specified as auto-extending.
As an example, assume that the tablespace has just one
auto-extending data file ibdata1:
innodb_data_home_dir = innodb_data_file_path = /ibdata/ibdata1:10M:autoextend
Suppose that this data file, over time, has grown to 988MB. Here is the configuration line after modifying the original data file to not be auto-extending and adding another auto-extending data file:
innodb_data_home_dir = innodb_data_file_path = /ibdata/ibdata1:988M;/disk2/ibdata2:50M:autoextend
When you add a new file to the tablespace configuration, make sure
that it does not exist. InnoDB will create and
initialize the file when you restart the server.
Currently, you cannot remove a data file from the tablespace. To decrease the size of your tablespace, use this procedure:
Use mysqldump to dump all your
InnoDBtables.Stop the server.
Remove all the existing tablespace files, including the
ibdataandib_logfiles. If you want to keep a backup copy of the information, then copy all theib*files to another location before the removing the files in your MySQL installation.Remove any
.frmfiles forInnoDBtables.Configure a new tablespace.
Restart the server.
Import the dump files.
If you want to change the number or the size of your
InnoDB log files, use the following
instructions. The procedure to use depends on the value of
innodb_fast_shutdown:
If
innodb_fast_shutdownis not set to 2: Stop the MySQL server and make sure that it shuts down without errors (to ensure that there is no information for outstanding transactions in the log). Copy the old log files into a safe place in case something went wrong during the shutdown and you need them to recover the tablespace. Delete the old log files from the log file directory, editmy.cnfto change the log file configuration, and start the MySQL server again. mysqld sees that noInnoDBlog files exist at startup and creates new ones.If
innodb_fast_shutdownis set to 2: Setinnodb_fast_shutdownto 1:mysql>
SET GLOBAL innodb_fast_shutdown = 1;Then follow the instructions in the previous item.
The key to safe database management is making regular backups.
InnoDB Hot Backup enables you to back up a
running MySQL database, including InnoDB and
MyISAM tables, with minimal disruption to
operations while producing a consistent snapshot of the database.
When InnoDB Hot Backup is copying
InnoDB tables, reads and writes to both
InnoDB and MyISAM tables can
continue. During the copying of MyISAM tables,
reads (but not writes) to those tables are permitted. In addition,
InnoDB Hot Backup supports creating compressed
backup files, and performing backups of subsets of
InnoDB tables. In conjunction with MySQL’s
binary log, users can perform point-in-time recovery.
InnoDB Hot Backup is commercially licensed by
Innobase Oy. For a more complete description of InnoDB
Hot Backup, see
http://www.innodb.com/hot-backup/features/ or
download the documentation from
http://www.innodb.com/doc/hot_backup/manual.html.
You can order trial, term, and perpetual licenses from Innobase at
http://www.innodb.com/hot-backup/order/.
If you are able to shut down your MySQL server, you can make a
binary backup that consists of all files used by
InnoDB to manage its tables. Use the following
procedure:
Shut down your MySQL server and make sure that it shuts down without errors.
Copy all your data files (
ibdatafiles and.ibdfiles) into a safe place.Copy all your
ib_logfilefiles to a safe place.Copy your
my.cnfconfiguration file or files to a safe place.Copy all the
.frmfiles for yourInnoDBtables to a safe place.
Replication works with InnoDB tables, so you
can use MySQL replication capabilities to keep a copy of your
database at database sites requiring high availability.
In addition to making binary backups as just described, you should
also regularly make dumps of your tables with
mysqldump. The reason for this is that a binary
file might be corrupted without you noticing it. Dumped tables are
stored into text files that are human-readable, so spotting table
corruption becomes easier. Also, because the format is simpler,
the chance for serious data corruption is smaller.
mysqldump also has a
--single-transaction option that
you can use to make a consistent snapshot without locking out
other clients. See Section 6.2.1, “Backup Policy”.
To be able to recover your InnoDB database to
the present from the binary backup just described, you have to run
your MySQL server with binary logging turned on. To achieve
point-in-time recovery after restoring a backup, you can apply
changes from the binary log that occurred after the backup was
made. See Section 6.3, “Point-in-Time Recovery”.
To recover from a crash of your MySQL server, the only requirement
is to restart it. InnoDB automatically checks
the logs and performs a roll-forward of the database to the
present. InnoDB automatically rolls back
uncommitted transactions that were present at the time of the
crash. During recovery, mysqld displays output
something like this:
InnoDB: Database was not shut down normally. InnoDB: Starting recovery from log files... InnoDB: Starting log scan based on checkpoint at InnoDB: log sequence number 0 13674004 InnoDB: Doing recovery: scanned up to log sequence number 0 13739520 InnoDB: Doing recovery: scanned up to log sequence number 0 13805056 InnoDB: Doing recovery: scanned up to log sequence number 0 13870592 InnoDB: Doing recovery: scanned up to log sequence number 0 13936128 ... InnoDB: Doing recovery: scanned up to log sequence number 0 20555264 InnoDB: Doing recovery: scanned up to log sequence number 0 20620800 InnoDB: Doing recovery: scanned up to log sequence number 0 20664692 InnoDB: 1 uncommitted transaction(s) which must be rolled back InnoDB: Starting rollback of uncommitted transactions InnoDB: Rolling back trx no 16745 InnoDB: Rolling back of trx no 16745 completed InnoDB: Rollback of uncommitted transactions completed InnoDB: Starting an apply batch of log records to the database... InnoDB: Apply batch completed InnoDB: Started mysqld: ready for connections
If your database gets corrupted or your disk fails, you have to do the recovery from a backup. In the case of corruption, you should first find a backup that is not corrupted. After restoring the base backup, do the recovery from the binary log files using mysqlbinlog and mysql to restore the changes that occurred after the backup was made.
In some cases of database corruption it is enough just to dump,
drop, and re-create one or a few corrupt tables. You can use the
CHECK TABLE SQL statement to check
whether a table is corrupt, although CHECK
TABLE naturally cannot detect every possible kind of
corruption. You can use the Tablespace Monitor to check the
integrity of the file space management inside the tablespace
files.
In some cases, apparent database page corruption is actually due to the operating system corrupting its own file cache, and the data on disk may be okay. It is best first to try restarting your computer. Doing so may eliminate errors that appeared to be database page corruption.
InnoDB crash recovery consists of several
steps. The first step, redo log application, is performed during
the initialization, before accepting any connections. If all
changes were flushed from the buffer pool to the tablespaces
(ibdata* and *.ibd
files) at the time of the shutdown or crash, the redo log
application can be skipped. If the redo log files are missing at
startup, InnoDB skips the redo log
application.
The remaining steps after redo log application do not depend on the redo log (other than for logging the writes) and are performed in parallel with normal processing. These include:
Rolling back incomplete transactions: Any transactions that were active at the time of crash or fast shutdown.
Insert buffer merge: Applying changes from the insert buffer tree (from the shared tablespace) to leaf pages of secondary indexes as the index pages are read to the buffer pool.
Purge: Deleting delete-marked records that are no longer visible for any active transaction.
Of these, only rollback of incomplete transactions is special to crash recovery. The insert buffer merge and the purge are performed during normal processing.
If there is database page corruption, you may want to dump your
tables from the database with SELECT INTO ...
OUTFILE. Usually, most of the data obtained in this
way is intact. However, it is possible that the corruption might
cause SELECT * FROM
statements or
tbl_nameInnoDB background operations to crash or
assert, or even cause InnoDB roll-forward
recovery to crash. In such cases, you can use the
innodb_force_recovery option to
force the InnoDB storage engine to start up
while preventing background operations from running, so that you
are able to dump your tables. For example, you can add the
following line to the [mysqld] section of
your option file before restarting the server:
[mysqld] innodb_force_recovery = 4
innodb_force_recovery is 0 by
default (normal startup without forced recovery) The allowable
nonzero values for
innodb_force_recovery follow. A
larger number includes all precautions of smaller numbers. If
you are able to dump your tables with an option value of at most
4, then you are relatively safe that only some data on corrupt
individual pages is lost. A value of 6 is more drastic because
database pages are left in an obsolete state, which in turn may
introduce more corruption into B-trees and other database
structures.
1(SRV_FORCE_IGNORE_CORRUPT)Let the server run even if it detects a corrupt page. Try to make
SELECT * FROMjump over corrupt index records and pages, which helps in dumping tables.tbl_name2(SRV_FORCE_NO_BACKGROUND)Prevent the main thread from running. If a crash would occur during the purge operation, this recovery value prevents it.
3(SRV_FORCE_NO_TRX_UNDO)Do not run transaction rollbacks after recovery.
4(SRV_FORCE_NO_IBUF_MERGE)Prevent insert buffer merge operations. If they would cause a crash, do not do them. Do not calculate table statistics.
5(SRV_FORCE_NO_UNDO_LOG_SCAN)Do not look at undo logs when starting the database:
InnoDBtreats even incomplete transactions as committed.6(SRV_FORCE_NO_LOG_REDO)Do not do the log roll-forward in connection with recovery.
The database must not otherwise be used with any
nonzero value of
innodb_force_recovery.
As a safety measure, InnoDB prevents users
from performing INSERT,
UPDATE, or
DELETE operations when
innodb_force_recovery is
greater than 0.
You can SELECT from tables to
dump them, or DROP or
CREATE tables even if forced recovery is
used. If you know that a given table is causing a crash on
rollback, you can drop it. You can also use this to stop a
runaway rollback caused by a failing mass import or
ALTER TABLE. You can kill the
mysqld process and set
innodb_force_recovery to
3 to bring the database up without the
rollback, then DROP the table that is causing
the runaway rollback.
InnoDB implements a checkpoint mechanism
known as “fuzzy” checkpointing.
InnoDB flushes modified database pages from
the buffer pool in small batches. There is no need to flush the
buffer pool in one single batch, which would in practice stop
processing of user SQL statements during the checkpointing
process.
During crash recovery, InnoDB looks for a
checkpoint label written to the log files. It knows that all
modifications to the database before the label are present in
the disk image of the database. Then InnoDB
scans the log files forward from the checkpoint, applying the
logged modifications to the database.
InnoDB writes to its log files on a rotating
basis. All committed modifications that make the database pages
in the buffer pool different from the images on disk must be
available in the log files in case InnoDB has
to do a recovery. This means that when InnoDB
starts to reuse a log file, it has to make sure that the
database page images on disk contain the modifications logged in
the log file that InnoDB is going to reuse.
In other words, InnoDB must create a
checkpoint and this often involves flushing of modified database
pages to disk.
The preceding description explains why making your log files very large may reduce disk I/O in checkpointing. It often makes sense to set the total size of the log files as large as the buffer pool or even larger. The disadvantage of using large log files is that crash recovery can take longer because there is more logged information to apply to the database.
On Windows, InnoDB always stores database and
table names internally in lowercase. To move databases in a binary
format from Unix to Windows or from Windows to Unix, you should
create all databases and tables using lowercase names. A
convenient way to accomplish this is to add the following line to
the [mysqld] section of your
my.cnf or my.ini file
before creating any databases or tables:
[mysqld] lower_case_table_names=1
Like MyISAM data files,
InnoDB data and log files are binary-compatible
on all platforms having the same floating-point number format. You
can move an InnoDB database simply by copying
all the relevant files listed in Section 13.2.6, “Backing Up and Recovering an InnoDB Database”.
If the floating-point formats differ but you have not used
FLOAT or
DOUBLE data types in your tables,
then the procedure is the same: simply copy the relevant files. If
you use mysqldump to dump your tables on one
machine and then import the dump files on the other machine, it
does not matter whether the formats differ or your tables contain
floating-point data.
One way to increase performance is to switch off autocommit mode when importing data, assuming that the tablespace has enough space for the big rollback segment that the import transactions generate. Do the commit only after importing a whole table or a segment of a table.
- 13.2.8.1.
InnoDBLock Modes - 13.2.8.2. Consistent Nonlocking Reads
- 13.2.8.3.
SELECT ... FOR UPDATEandSELECT ... LOCK IN SHARE MODELocking Reads - 13.2.8.4.
InnoDBRecord, Gap, and Next-Key Locks - 13.2.8.5. Avoiding the Phantom Problem Using Next-Key Locking
- 13.2.8.6. Locks Set by Different SQL Statements in
InnoDB - 13.2.8.7. Implicit Transaction Commit and Rollback
- 13.2.8.8. Deadlock Detection and Rollback
- 13.2.8.9. How to Cope with Deadlocks
In the InnoDB transaction model, the goal is to
combine the best properties of a multi-versioning database with
traditional two-phase locking. InnoDB does
locking on the row level and runs queries as nonlocking consistent
reads by default, in the style of Oracle. The lock table in
InnoDB is stored so space-efficiently that lock
escalation is not needed: Typically several users are allowed to
lock every row in InnoDB tables, or any random
subset of the rows, without causing InnoDB
memory exhaustion.
In InnoDB, all user activity occurs inside a
transaction. If autocommit mode is enabled, each SQL statement
forms a single transaction on its own. By default, MySQL starts
the session for each new connection with autocommit enabled, so
MySQL does a commit after each SQL statement if that statement did
not return an error. If a statement returns an error, the commit
or rollback behavior depends on the error. See
Section 13.2.12, “InnoDB Error Handling”.
A session that has autocommit enabled can perform a
multiple-statement transaction by starting it with an explicit
START
TRANSACTION or
BEGIN statement
and ending it with a COMMIT or
ROLLBACK
statement.
If autocommit mode is disabled within a session with SET
autocommit = 0, the session always has a transaction
open. A COMMIT or
ROLLBACK
statement ends the current transaction and a new one starts.
A COMMIT means that the changes
made in the current transaction are made permanent and become
visible to other sessions. A
ROLLBACK
statement, on the other hand, cancels all modifications made by
the current transaction. Both
COMMIT and
ROLLBACK release
all InnoDB locks that were set during the
current transaction.
In terms of the SQL:1992 transaction isolation levels, the default
InnoDB level is
REPEATABLE READ.
InnoDB offers all four transaction isolation
levels described by the SQL standard:
READ UNCOMMITTED,
READ COMMITTED,
REPEATABLE READ, and
SERIALIZABLE.
A user can change the isolation level for a single session or for
all subsequent connections with the SET
TRANSACTION statement. To set the server's default
isolation level for all connections, use the
--transaction-isolation option on
the command line or in an option file. For detailed information
about isolation levels and level-setting syntax, see
Section 12.4.6, “SET TRANSACTION Syntax”.
In row-level locking, InnoDB normally uses
next-key locking. That means that besides index records,
InnoDB can also lock the “gap”
preceding an index record to block insertions by other sessions in
the gap immediately before the index record. A next-key lock
refers to a lock that locks an index record and the gap before it.
A gap lock refers to a lock that locks only the gap before some
index record.
For more information about row-level locking, and the
circumstances under which gap locking is disabled, see
Section 13.2.8.4, “InnoDB Record, Gap, and Next-Key Locks”.
InnoDB implements standard row-level locking
where there are two types of locks:
A shared (
S) lock allows a transaction to read a row.An exclusive (
X) lock allows a transaction to update or delete a row.
If transaction T1 holds a shared
(S) lock on row r,
then requests from some distinct transaction
T2 for a lock on row r are
handled as follows:
A request by
T2for anSlock can be granted immediately. As a result, bothT1andT2hold anSlock onr.A request by
T2for anXlock cannot be granted immediately.
If a transaction T1 holds an exclusive
(X) lock on row r,
a request from some distinct transaction T2
for a lock of either type on r cannot be
granted immediately. Instead, transaction T2
has to wait for transaction T1 to release its
lock on row r.
Additionally, InnoDB supports
multiple granularity locking which allows
coexistence of record locks and locks on entire tables. To make
locking at multiple granularity levels practical, additional
types of locks called intention locks are
used. Intention locks are table locks in
InnoDB. The idea behind intention locks is
for a transaction to indicate which type of lock (shared or
exclusive) it will require later for a row in that table. There
are two types of intention locks used in
InnoDB (assume that transaction
T has requested a lock of the indicated type
on table t):
Intention shared (
IS): TransactionTintends to setSlocks on individual rows in tablet.Intention exclusive (
IX): TransactionTintends to setXlocks on those rows.
For example, SELECT ...
LOCK IN SHARE MODE sets an
IS lock and
SELECT ... FOR
UPDATE sets an IX lock.
The intention locking protocol is as follows:
Before a transaction can acquire an
Slock on a row in tablet, it must first acquire anISor stronger lock ont.Before a transaction can acquire an
Xlock on a row, it must first acquire anIXlock ont.
These rules can be conveniently summarized by means of the following lock type compatibility matrix.
X | IX | S | IS | |
X | Conflict | Conflict | Conflict | Conflict |
IX | Conflict | Compatible | Conflict | Compatible |
S | Conflict | Conflict | Compatible | Compatible |
IS | Conflict | Compatible | Compatible | Compatible |
A lock is granted to a requesting transaction if it is compatible with existing locks, but not if it conflicts with existing locks. A transaction waits until the conflicting existing lock is released. If a lock request conflicts with an existing lock and cannot be granted because it would cause deadlock, an error occurs.
Thus, intention locks do not block anything except full table
requests (for example, LOCK TABLES ...
WRITE). The main purpose of
IX and IS
locks is to show that someone is locking a row, or going to lock
a row in the table.
The following example illustrates how an error can occur when a lock request would cause a deadlock. The example involves two clients, A and B.
First, client A creates a table containing one row, and then
begins a transaction. Within the transaction, A obtains an
S lock on the row by selecting it in
share mode:
mysql>CREATE TABLE t (i INT) ENGINE = InnoDB;Query OK, 0 rows affected (1.07 sec) mysql>INSERT INTO t (i) VALUES(1);Query OK, 1 row affected (0.09 sec) mysql>START TRANSACTION;Query OK, 0 rows affected (0.00 sec) mysql>SELECT * FROM t WHERE i = 1 LOCK IN SHARE MODE;+------+ | i | +------+ | 1 | +------+ 1 row in set (0.10 sec)
Next, client B begins a transaction and attempts to delete the row from the table:
mysql>START TRANSACTION;Query OK, 0 rows affected (0.00 sec) mysql>DELETE FROM t WHERE i = 1;
The delete operation requires an X
lock. The lock cannot be granted because it is incompatible with
the S lock that client A holds, so
the request goes on the queue of lock requests for the row and
client B blocks.
Finally, client A also attempts to delete the row from the table:
mysql> DELETE FROM t WHERE i = 1;
ERROR 1213 (40001): Deadlock found when trying to get lock;
try restarting transaction
Deadlock occurs here because client A needs an
X lock to delete the row. However,
that lock request cannot be granted because client B already has
a request for an X lock and is
waiting for client A to release its S
lock. Nor can the S lock held by A be
upgraded to an X lock because of the
prior request by B for an X lock. As
a result, InnoDB generates an error for
client A and releases its locks. At that point, the lock request
for client B can be granted and B deletes the row from the
table.
A consistent read means that InnoDB uses
multi-versioning to present to a query a snapshot of the
database at a point in time. The query sees the changes made by
transactions that committed before that point of time, and no
changes made by later or uncommitted transactions. The exception
to this rule is that the query sees the changes made by earlier
statements within the same transaction. This exception causes
the following anomaly: If you update some rows in a table, a
SELECT will see the latest
version of the updated rows, but it might also see older
versions of any rows. If other sessions simultaneously update
the same table, the anomaly means that you may see the table in
a state that never existed in the database.
If the transaction isolation level is
REPEATABLE READ (the default
level), all consistent reads within the same transaction read
the snapshot established by the first such read in that
transaction. You can get a fresher snapshot for your queries by
committing the current transaction and after that issuing new
queries.
With READ COMMITTED isolation
level, each consistent read within a transaction sets and reads
its own fresh snapshot.
Consistent read is the default mode in which
InnoDB processes
SELECT statements in
READ COMMITTED and
REPEATABLE READ isolation
levels. A consistent read does not set any locks on the tables
it accesses, and therefore other sessions are free to modify
those tables at the same time a consistent read is being
performed on the table.
Suppose that you are running in the default
REPEATABLE READ isolation
level. When you issue a consistent read (that is, an ordinary
SELECT statement),
InnoDB gives your transaction a timepoint
according to which your query sees the database. If another
transaction deletes a row and commits after your timepoint was
assigned, you do not see the row as having been deleted. Inserts
and updates are treated similarly.
You can advance your timepoint by committing your transaction
and then doing another SELECT.
This is called multi-versioned concurrency control.
In the following example, session A sees the row inserted by B only when B has committed the insert and A has committed as well, so that the timepoint is advanced past the commit of B.
Session A Session B
SET autocommit=0; SET autocommit=0;
time
| SELECT * FROM t;
| empty set
| INSERT INTO t VALUES (1, 2);
|
v SELECT * FROM t;
empty set
COMMIT;
SELECT * FROM t;
empty set
COMMIT;
SELECT * FROM t;
---------------------
| 1 | 2 |
---------------------
1 row in set
If you want to see the “freshest” state of the
database, you should use either the
READ COMMITTED isolation
level or a locking read:
SELECT * FROM t LOCK IN SHARE MODE;
With READ COMMITTED isolation
level, each consistent read within a transaction sets and reads
its own fresh snapshot. With LOCK IN SHARE
MODE, a locking read occurs instead: A
SELECT blocks until the transaction
containing the freshest rows ends (see
Section 13.2.8.3, “SELECT ... FOR UPDATE
and SELECT ... LOCK IN
SHARE MODE Locking Reads”).
Consistent read does not work over DROP
TABLE or over ALTER
TABLE:
Consistent read does not work over
DROP TABLEbecause MySQL cannot use a table that has been dropped andInnoDBdestroys the table.Consistent read does not work over
ALTER TABLEbecauseALTER TABLEworks by making a temporary copy of the original table and deleting the original table when the temporary copy is built. When you reissue a consistent read within a transaction, rows in the new table are not visible because those rows did not exist when the transaction's snapshot was taken.
InnoDB uses a consistent read for select in
clauses like INSERT INTO
... SELECT,
UPDATE ...
(SELECT), and
CREATE TABLE ...
SELECT that do not specify FOR
UPDATE or LOCK IN SHARE MODE if the
innodb_locks_unsafe_for_binlog
option is set and the isolation level of the transaction is not
set to SERIALIZABLE. Thus, no
locks are set on rows read from the selected table. Otherwise,
InnoDB uses stronger locks and the
SELECT part acts like
READ COMMITTED, where each
consistent read, even within the same transaction, sets and
reads its own fresh snapshot.
In some circumstances, a consistent (nonlocking) read is not
convenient and a locking read is required instead.
InnoDB supports two types of locking reads:
SELECT ... LOCK IN SHARE MODEsets a shared mode lock on the rows read. A shared mode lock enables other sessions to read the rows but not to modify them. The rows read are the latest available, so if they belong to another transaction that has not yet committed, the read blocks until that transaction ends.For index records the search encounters,
SELECT ... FOR UPDATEblocks other sessions from doingSELECT ... LOCK IN SHARE MODEor from reading in certain transaction isolation levels. Consistent reads will ignore any locks set on the records that exist in the read view. (Old versions of a record cannot be locked; they will be reconstructed by applying undo logs on an in-memory copy of the record.)
Locks set by LOCK IN SHARE MODE and
FOR UPDATE reads are released when the
transaction is committed or rolled back.
As an example of a situation in which a locking read is useful,
suppose that you want to insert a new row into a table
child, and make sure that the child row has a
parent row in table parent. The following
discussion describes how to implement referential integrity in
application code.
Suppose that you use a consistent read to read the table
parent and indeed see the parent row of the
to-be-inserted child row in the table. Can you safely insert the
child row to table child? No, because it is
possible for some other session to delete the parent row from
the table parent in the meantime without you
being aware of it.
The solution is to perform the
SELECT in a locking mode using
LOCK IN SHARE MODE:
SELECT * FROM parent WHERE NAME = 'Jones' LOCK IN SHARE MODE;
A read performed with LOCK IN SHARE MODE
reads the latest available data and sets a shared mode lock on
the rows read. A shared mode lock prevents others from updating
or deleting the row read. Also, if the latest data belongs to a
yet uncommitted transaction of another session, we wait until
that transaction ends. After we see that the LOCK IN
SHARE MODE query returns the parent
'Jones', we can safely add the child record
to the child table and commit our
transaction.
Let us look at another example: We have an integer counter field
in a table child_codes that we use to assign
a unique identifier to each child added to table
child. It is not a good idea to use either
consistent read or a shared mode read to read the present value
of the counter because two users of the database may then see
the same value for the counter, and a duplicate-key error occurs
if two users attempt to add children with the same identifier to
the table.
Here, LOCK IN SHARE MODE is not a good
solution because if two users read the counter at the same time,
at least one of them ends up in deadlock when it attempts to
update the counter.
In this case, there are two good ways to implement reading and incrementing the counter:
First update the counter by incrementing it by 1, and then read it.
First perform a locking read of the counter using
FOR UPDATE, and then increment the counter.
The latter approach can be implemented as follows:
SELECT counter_field FROM child_codes FOR UPDATE; UPDATE child_codes SET counter_field = counter_field + 1;
A SELECT ... FOR
UPDATE reads the latest available data, setting
exclusive locks on each row it reads. Thus, it sets the same
locks a searched SQL UPDATE would
set on the rows.
The preceding description is merely an example of how
SELECT ... FOR
UPDATE works. In MySQL, the specific task of
generating a unique identifier actually can be accomplished
using only a single access to the table:
UPDATE child_codes SET counter_field = LAST_INSERT_ID(counter_field + 1); SELECT LAST_INSERT_ID();
The SELECT statement merely
retrieves the identifier information (specific to the current
connection). It does not access any table.
Note
Locking of rows for update using SELECT FOR
UPDATE only applies when autocommit is disabled
(either by beginning transaction with
START
TRANSACTION or by setting
autocommit to 0. If
autocommit is enabled, the rows matching the specification are
not locked.
InnoDB has several types of record-level
locks:
Record lock: This is a lock on an index record.
Gap lock: This is a lock on a gap between index records, or a lock on the gap before the first or after the last index record.
Next-key lock: This is a combination of a record lock on the index record and a gap lock on the gap before the index record.
Record locks always lock index records, even if a table is
defined with no indexes. For such cases,
InnoDB creates a hidden clustered index and
uses this index for record locking. See
Section 13.2.10.1, “Clustered and Secondary Indexes”.
By default, InnoDB operates in
REPEATABLE READ transaction
isolation level and with the
innodb_locks_unsafe_for_binlog
system variable disabled. In this case,
InnoDB uses next-key locks for searches and
index scans, which prevents phantom rows (see
Section 13.2.8.5, “Avoiding the Phantom Problem Using Next-Key Locking”).
Next-key locking combines index-row locking with gap locking.
InnoDB performs row-level locking in such a
way that when it searches or scans a table index, it sets shared
or exclusive locks on the index records it encounters. Thus, the
row-level locks are actually index-record locks. In addition, a
next-key lock on an index record also affects the
“gap” before that index record. That is, a next-key
lock is an index-record lock plus a gap lock on the gap
preceding the index record. If one session has a shared or
exclusive lock on record R in an index,
another session cannot insert a new index record in the gap
immediately before R in the index order.
Suppose that an index contains the values 10, 11, 13, and 20.
The possible next-key locks for this index cover the following
intervals, where ( or )
denote exclusion of the interval endpoint and
[ or ] denote inclusion of
the endpoint:
(negative infinity, 10] (10, 11] (11, 13] (13, 20] (20, positive infinity)
For the last interval, the next-key lock locks the gap above the largest value in the index and the “supremum” pseudo-record having a value higher than any value actually in the index. The supremum is not a real index record, so, in effect, this next-key lock locks only the gap following the largest index value.
The preceding example shows that a gap might span a single index value, multiple index values, or even be empty.
Gap locking is not needed for statements that lock rows using a
unique index to search for a unique row. For example, if the
id column has a unique index, the following
statement uses only an index-record lock for the row having
id value 100 and it does not matter whether
other sessions insert rows in the preceding gap:
SELECT * FROM child WHERE id = 100;
If id is not indexed or has a nonunique
index, the statement does lock the preceding gap.
A type of gap lock called an insertion intention gap lock is set
by INSERT operations prior to row
insertion. This lock signals the intent to insert in such a way
that multiple transactions inserting into the same index gap
need not wait for each other if they are not inserting at the
same position within the gap. Suppose that there are index
records with values of 4 and 7. Separate transactions that
attempt to insert values of 5 and 6 each lock the gap between 4
and 7 with insert intention locks prior to obtaining the
exclusive lock on the inserted row, but do not block each other
because the rows are nonconflicting.
Gap locking can be disabled explicitly. This occurs if you
change the transaction isolation level to
READ COMMITTED or enable the
innodb_locks_unsafe_for_binlog
system variable. Under these circumstances, gap locking is
disabled for searches and index scans and is used only for
foreign-key constraint checking and duplicate-key checking.
There is also another effect of using the
READ COMMITTED isolation
level or enabling
innodb_locks_unsafe_for_binlog:
Record locks for nonmatching rows are released after MySQL has
evaluated the WHERE condition.
The so-called phantom problem occurs
within a transaction when the same query produces different sets
of rows at different times. For example, if a
SELECT is executed twice, but
returns a row the second time that was not returned the first
time, the row is a “phantom” row.
Suppose that there is an index on the id
column of the child table and that you want
to read and lock all rows from the table having an identifier
value larger than 100, with the intention of updating some
column in the selected rows later:
SELECT * FROM child WHERE id > 100 FOR UPDATE;
The query scans the index starting from the first record where
id is bigger than 100. Let the table contain
rows having id values of 90 and 102. If the
locks set on the index records in the scanned range do not lock
out inserts made in the gaps (in this case, the gap between 90
and 102), another session can insert a new row into the table
with an id of 101. If you were to execute the
same SELECT within the same
transaction, you would see a new row with an
id of 101 (a “phantom”) in the
result set returned by the query. If we regard a set of rows as
a data item, the new phantom child would violate the isolation
principle of transactions that a transaction should be able to
run so that the data it has read does not change during the
transaction.
To prevent phantoms, InnoDB uses an algorithm
called next-key locking that combines
index-row locking with gap locking. InnoDB
performs row-level locking in such a way that when it searches
or scans a table index, it sets shared or exclusive locks on the
index records it encounters. Thus, the row-level locks are
actually index-record locks. In addition, a next-key lock on an
index record also affects the “gap” before that
index record. That is, a next-key lock is an index-record lock
plus a gap lock on the gap preceding the index record. If one
session has a shared or exclusive lock on record
R in an index, another session cannot insert
a new index record in the gap immediately before
R in the index order.
When InnoDB scans an index, it can also lock
the gap after the last record in the index. Just that happens in
the preceding example: To prevent any insert into the table
where id would be bigger than 100, the locks
set by InnoDB include a lock on the gap
following id value 102.
You can use next-key locking to implement a uniqueness check in your application: If you read your data in share mode and do not see a duplicate for a row you are going to insert, then you can safely insert your row and know that the next-key lock set on the successor of your row during the read prevents anyone meanwhile inserting a duplicate for your row. Thus, the next-key locking allows you to “lock” the nonexistence of something in your table.
Gap locking can be disabled as discussed in
Section 13.2.8.4, “InnoDB Record, Gap, and Next-Key Locks”. This may cause
phantom problems because other sessions can insert new rows into
the gaps when gap locking is disabled.
A locking read, an UPDATE, or a
DELETE generally set record locks
on every index record that is scanned in the processing of the
SQL statement. It does not matter whether there are
WHERE conditions in the statement that would
exclude the row. InnoDB does not remember the
exact WHERE condition, but only knows which
index ranges were scanned. The locks are normally next-key locks
that also block inserts into the “gap” immediately
before the record. However, gap locking can be disabled
explicitly, which causes next-key locking not to be used. For
more information, see
Section 13.2.8.4, “InnoDB Record, Gap, and Next-Key Locks”.
Differences between shared and exclusive locks are described in
Section 13.2.8.1, “InnoDB Lock Modes”.
If you have no indexes suitable for your statement and MySQL must scan the entire table to process the statement, every row of the table becomes locked, which in turn blocks all inserts by other users to the table. It is important to create good indexes so that your queries do not unnecessarily scan many rows.
For SELECT ... FOR
UPDATE or
SELECT ... LOCK IN SHARE
MODE, locks are acquired for scanned rows, and
expected to be released for rows that do not qualify for
inclusion in the result set (for example, if they do not meet
the criteria given in the WHERE clause).
However, in some cases, rows might not be unlocked immediately
because the relationship between a result row and its original
source is lost during query execution. For example, in a
UNION, scanned (and locked) rows
from a table might be inserted into a temporary table before
evaluation whether they qualify for the result set. In this
circumstance, the relationship of the rows in the temporary
table to the rows in the original table is lost and the latter
rows are not unlocked until the end of query execution.
InnoDB sets specific types of locks as
follows. If a secondary index is used in the search and index
record locks to be set are exclusive, InnoDB
also retrieves the corresponding clustered index records and
sets locks on them.
SELECT ... FROMis a consistent read, reading a snapshot of the database and setting no locks unless the transaction isolation level is set toSERIALIZABLE. ForSERIALIZABLElevel, the search sets shared next-key locks on the index records it encounters.SELECT ... FROM ... LOCK IN SHARE MODEsets shared next-key locks on all index records the search encounters.For index records the search encounters,
SELECT ... FROM ... FOR UPDATEblocks other sessions from doingSELECT ... FROM ... LOCK IN SHARE MODEor from reading in certain transaction isolation levels. Consistent reads will ignore any locks set on the records that exist in the read view.UPDATE ... WHERE ...sets an exclusive next-key lock on every record the search encounters.DELETE FROM ... WHERE ...sets an exclusive next-key lock on every record the search encounters.INSERTsets an exclusive lock on the inserted row. This lock is an index-record lock, not a next-key lock (that is, there is no gap lock) and does not prevent other sessions from inserting into the gap before the inserted row.Prior to inserting the row, a type of gap lock called an insertion intention gap lock is set. This lock signals the intent to insert in such a way that multiple transactions inserting into the same index gap need not wait for each other if they are not inserting at the same position within the gap. Suppose that there are index records with values of 4 and 7. Separate transactions that attempt to insert values of 5 and 6 each lock the gap between 4 and 7 with insert intention locks prior to obtaining the exclusive lock on the inserted row, but do not block each other because the rows are nonconflicting.
If a duplicate-key error occurs, a shared lock on the duplicate index record is set. This use of a shared lock can result in deadlock should there be multiple sessions trying to insert the same row if another session already has an exclusive lock. This can occur if another session deletes the row. Suppose that an
InnoDBtablet1has the following structure:CREATE TABLE t1 (i INT, PRIMARY KEY (i)) ENGINE = InnoDB;
Now suppose that three sessions perform the following operations in order:
Session 1:
START TRANSACTION; INSERT INTO t1 VALUES(1);
Session 2:
START TRANSACTION; INSERT INTO t1 VALUES(1);
Session 3:
START TRANSACTION; INSERT INTO t1 VALUES(1);
Session 1:
ROLLBACK;
The first operation by session 1 acquires an exclusive lock for the row. The operations by sessions 2 and 3 both result in a duplicate-key error and they both request a shared lock for the row. When session 1 rolls back, it releases its exclusive lock on the row and the queued shared lock requests for sessions 2 and 3 are granted. At this point, sessions 2 and 3 deadlock: Neither can acquire an exclusive lock for the row because of the shared lock held by the other.
A similar situation occurs if the table already contains a row with key value 1 and three sessions perform the following operations in order:
Session 1:
START TRANSACTION; DELETE FROM t1 WHERE i = 1;
Session 2:
START TRANSACTION; INSERT INTO t1 VALUES(1);
Session 3:
START TRANSACTION; INSERT INTO t1 VALUES(1);
Session 1:
COMMIT;
The first operation by session 1 acquires an exclusive lock for the row. The operations by sessions 2 and 3 both result in a duplicate-key error and they both request a shared lock for the row. When session 1 commits, it releases its exclusive lock on the row and the queued shared lock requests for sessions 2 and 3 are granted. At this point, sessions 2 and 3 deadlock: Neither can acquire an exclusive lock for the row because of the shared lock held by the other.
REPLACEis done like anINSERTif there is no collision on a unique key. Otherwise, an exclusive next-key lock is placed on the row that must be updated.INSERT INTO T SELECT ... FROM S WHERE ...sets an exclusive index record without a gap lock on each row inserted intoT. Ifinnodb_locks_unsafe_for_binlogis enabled or the transaction isolation level isREAD COMMITTED,InnoDBdoes the search onSas a consistent read (no locks). Otherwise,InnoDBsets shared next-key locks on rows fromS.InnoDBhas to set locks in the latter case: In roll-forward recovery from a backup, every SQL statement must be executed in exactly the same way it was done originally.CREATE TABLE ... SELECT ...performs theSELECTwith shared next-key locks or as a consistent read, as forINSERT ... SELECT.For
REPLACE INTO T SELECT ... FROM S WHERE ...,InnoDBsets shared next-key locks on rows fromS.While initializing a previously specified
AUTO_INCREMENTcolumn on a table,InnoDBsets an exclusive lock on the end of the index associated with theAUTO_INCREMENTcolumn. In accessing the auto-increment counter,InnoDBuses a specificAUTO-INCtable lock mode where the lock lasts only to the end of the current SQL statement, not to the end of the entire transaction. Other sessions cannot insert into the table while theAUTO-INCtable lock is held; see Section 13.2.8, “TheInnoDBTransaction Model and Locking”.InnoDBfetches the value of a previously initializedAUTO_INCREMENTcolumn without setting any locks.If a
FOREIGN KEYconstraint is defined on a table, any insert, update, or delete that requires the constraint condition to be checked sets shared record-level locks on the records that it looks at to check the constraint.InnoDBalso sets these locks in the case where the constraint fails.LOCK TABLESsets table locks, but it is the higher MySQL layer above theInnoDBlayer that sets these locks.InnoDBis aware of table locks ifinnodb_table_locks = 1(the default) andautocommit = 0, and the MySQL layer aboveInnoDBknows about row-level locks.Otherwise,
InnoDB's automatic deadlock detection cannot detect deadlocks where such table locks are involved. Also, because in this case the higher MySQL layer does not know about row-level locks, it is possible to get a table lock on a table where another session currently has row-level locks. However, this does not endanger transaction integrity, as discussed in Section 13.2.8.8, “Deadlock Detection and Rollback”. See also Section 13.2.14, “Restrictions onInnoDBTables”.
By default, MySQL starts the session for each new connection
with autocommit mode enabled, so MySQL does a commit after each
SQL statement if that statement did not return an error. If a
statement returns an error, the commit or rollback behavior
depends on the error. See
Section 13.2.12, “InnoDB Error Handling”.
If a session that has autocommit disabled ends without explicitly committing the final transaction, MySQL rolls back that transaction.
Some statements implicitly end a transaction, as if you had done
a COMMIT before executing the
statement. For details, see Section 12.4.3, “Statements That Cause an Implicit Commit”.
InnoDB automatically detects transaction
deadlocks and rolls back a transaction or transactions to break
the deadlock. InnoDB tries to pick small
transactions to roll back, where the size of a transaction is
determined by the number of rows inserted, updated, or deleted.
InnoDB is aware of table locks if
innodb_table_locks = 1 (the default) and
autocommit = 0, and the MySQL
layer above it knows about row-level locks. Otherwise,
InnoDB cannot detect deadlocks where a table
lock set by a MySQL LOCK TABLES
statement or a lock set by a storage engine other than
InnoDB is involved. You must resolve these
situations by setting the value of the
innodb_lock_wait_timeout system
variable.
When InnoDB performs a complete rollback of a
transaction, all locks set by the transaction are released.
However, if just a single SQL statement is rolled back as a
result of an error, some of the locks set by the statement may
be preserved. This happens because InnoDB
stores row locks in a format such that it cannot know afterward
which lock was set by which statement.
Deadlocks are a classic problem in transactional databases, but they are not dangerous unless they are so frequent that you cannot run certain transactions at all. Normally, you must write your applications so that they are always prepared to re-issue a transaction if it gets rolled back because of a deadlock.
InnoDB uses automatic row-level locking. You
can get deadlocks even in the case of transactions that just
insert or delete a single row. That is because these operations
are not really “atomic”; they automatically set
locks on the (possibly several) index records of the row
inserted or deleted.
You can cope with deadlocks and reduce the likelihood of their occurrence with the following techniques:
Use
SHOW ENGINE INNODB STATUSto determine the cause of the latest deadlock. That can help you to tune your application to avoid deadlocks.Always be prepared to re-issue a transaction if it fails due to deadlock. Deadlocks are not dangerous. Just try again.
Commit your transactions often. Small transactions are less prone to collision.
If you are using locking reads (
SELECT ... FOR UPDATEorSELECT ... LOCK IN SHARE MODE), try using a lower isolation level such asREAD COMMITTED.Access your tables and rows in a fixed order. Then transactions form well-defined queues and do not deadlock.
Add well-chosen indexes to your tables. Then your queries need to scan fewer index records and consequently set fewer locks. Use
EXPLAIN SELECTto determine which indexes the MySQL server regards as the most appropriate for your queries.Use less locking. If you can afford to allow a
SELECTto return data from an old snapshot, do not add the clauseFOR UPDATEorLOCK IN SHARE MODEto it. Using theREAD COMMITTEDisolation level is good here, because each consistent read within the same transaction reads from its own fresh snapshot. You should also set the value ofinnodb_support_xato 0, which will reduce the number of disk flushes due to synchronizing on disk data and the binary log.If nothing else helps, serialize your transactions with table-level locks. The correct way to use
LOCK TABLESwith transactional tables, such asInnoDBtables, is to begin a transaction withSET autocommit = 0(notSTART TRANSACTION) followed byLOCK TABLES, and to not callUNLOCK TABLESuntil you commit the transaction explicitly. For example, if you need to write to tablet1and read from tablet2, you can do this:SET autocommit=0; LOCK TABLES t1 WRITE, t2 READ, ...;
... do something with tables t1 and t2 here ...COMMIT; UNLOCK TABLES;Table-level locks make your transactions queue nicely and avoid deadlocks.
Another way to serialize transactions is to create an auxiliary “semaphore” table that contains just a single row. Have each transaction update that row before accessing other tables. In that way, all transactions happen in a serial fashion. Note that the
InnoDBinstant deadlock detection algorithm also works in this case, because the serializing lock is a row-level lock. With MySQL table-level locks, the timeout method must be used to resolve deadlocks.
Because InnoDB is a multi-versioned storage
engine, it must keep information about old versions of rows in the
tablespace. This information is stored in a data structure called
a rollback segment (after an analogous data
structure in Oracle).
Internally, InnoDB adds three fields to each
row stored in the database. A 6-byte DB_TRX_ID
field indicates the transaction identifier for the last
transaction that inserted or updated the row. Also, a deletion is
treated internally as an update where a special bit in the row is
set to mark it as deleted. Each row also contains a 7-byte
DB_ROLL_PTR field called the roll pointer. The
roll pointer points to an undo log record written to the rollback
segment. If the row was updated, the undo log record contains the
information necessary to rebuild the content of the row before it
was updated. A 6-byte DB_ROW_ID field contains
a row ID that increases monotonically as new rows are inserted. If
InnoDB generates a clustered index
automatically, the index contains row ID values. Otherwise, the
DB_ROW_ID column does not appear in any index.
InnoDB uses the information in the rollback
segment to perform the undo operations needed in a transaction
rollback. It also uses the information to build earlier versions
of a row for a consistent read.
Undo logs in the rollback segment are divided into insert and
update undo logs. Insert undo logs are needed only in transaction
rollback and can be discarded as soon as the transaction commits.
Update undo logs are used also in consistent reads, but they can
be discarded only after there is no transaction present for which
InnoDB has assigned a snapshot that in a
consistent read could need the information in the update undo log
to build an earlier version of a database row.
You must remember to commit your transactions regularly, including
those transactions that issue only consistent reads. Otherwise,
InnoDB cannot discard data from the update undo
logs, and the rollback segment may grow too big, filling up your
tablespace.
The physical size of an undo log record in the rollback segment is typically smaller than the corresponding inserted or updated row. You can use this information to calculate the space need for your rollback segment.
In the InnoDB multi-versioning scheme, a row is
not physically removed from the database immediately when you
delete it with an SQL statement. Only when
InnoDB can discard the update undo log record
written for the deletion can it also physically remove the
corresponding row and its index records from the database. This
removal operation is called a purge, and it is quite fast, usually
taking the same order of time as the SQL statement that did the
deletion.
In a scenario where the user inserts and deletes rows in smallish
batches at about the same rate in the table, it is possible that
the purge thread starts to lag behind, and the table grows bigger
and bigger, making everything disk-bound and very slow. Even if
the table carries just 10MB of useful data, it may grow to occupy
10GB with all the “dead” rows. In such a case, it
would be good to throttle new row operations and allocate more
resources to the purge thread. The
innodb_max_purge_lag system
variable exists for exactly this purpose. See
Section 13.2.3, “InnoDB Startup Options and System Variables”, for more information.
MySQL stores its data dictionary information for tables in
.frm files in database directories. This is
true for all MySQL storage engines, but every
InnoDB table also has its own entry in the
InnoDB internal data dictionary inside the
tablespace. When MySQL drops a table or a database, it has to
delete one or more .frm files as well as the
corresponding entries inside the InnoDB data
dictionary. Consequently, you cannot move
InnoDB tables between databases simply by
moving the .frm files.
Every InnoDB table has a special index called
the clustered index where the data for
the rows is stored:
If you define a
PRIMARY KEYon your table,InnoDBuses it as the clustered index.If you do not define a
PRIMARY KEYfor your table, MySQL picks the firstUNIQUEindex that has onlyNOT NULLcolumns as the primary key andInnoDBuses it as the clustered index.If the table has no
PRIMARY KEYor suitableUNIQUEindex,InnoDBinternally generates a hidden clustered index on a synthetic column containing row ID values. The rows are ordered by the ID thatInnoDBassigns to the rows in such a table. The row ID is a 6-byte field that increases monotonically as new rows are inserted. Thus, the rows ordered by the row ID are physically in insertion order.
Accessing a row through the clustered index is fast because the
row data is on the same page where the index search leads. If a
table is large, the clustered index architecture often saves a
disk I/O operation when compared to storage organizations that
store row data using a different page from the index record.
(For example, MyISAM uses one file for data
rows and another for index records.)
In InnoDB, the records in nonclustered
indexes (also called secondary indexes) contain the primary key
columns for the row that are not in the secondary index.
InnoDB uses this primary key value to search
for the row in the clustered index. If the primary key is long,
the secondary indexes use more space, so it is advantageous to
have a short primary key.
All InnoDB indexes are B-trees where the
index records are stored in the leaf pages of the tree. The
default size of an index page is 16KB. When new records are
inserted, InnoDB tries to leave 1/16 of the
page free for future insertions and updates of the index
records.
If index records are inserted in a sequential order (ascending
or descending), the resulting index pages are about 15/16 full.
If records are inserted in a random order, the pages are from
1/2 to 15/16 full. If the fill factor of an index page drops
below 1/2, InnoDB tries to contract the index
tree to free the page.
It is a common situation in database applications that the primary key is a unique identifier and new rows are inserted in the ascending order of the primary key. Thus, insertions into the clustered index do not require random reads from a disk.
On the other hand, secondary indexes are usually nonunique, and
insertions into secondary indexes happen in a relatively random
order. This would cause a lot of random disk I/O operations
without a special mechanism used in InnoDB.
If an index record should be inserted into a nonunique secondary
index, InnoDB checks whether the secondary
index page is in the buffer pool. If that is the case,
InnoDB does the insertion directly to the
index page. If the index page is not found in the buffer pool,
InnoDB inserts the record to a special insert
buffer structure. The insert buffer is kept so small that it
fits entirely in the buffer pool, and insertions can be done
very fast.
Periodically, the insert buffer is merged into the secondary index trees in the database. Often it is possible to merge several insertions into the same page of the index tree, saving disk I/O operations. It has been measured that the insert buffer can speed up insertions into a table up to 15 times.
The insert buffer merging may continue to happen
after the inserting transaction has been
committed. In fact, it may continue to happen after a server
shutdown and restart (see Section 13.2.6.2, “Forcing InnoDB Recovery”).
Insert buffer merging may take many hours when many secondary
indexes must be updated and many rows have been inserted. During
this time, disk I/O will be increased, which can cause
significant slowdown on disk-bound queries. Another significant
background I/O operation is the purge thread (see
Section 13.2.9, “InnoDB Multi-Versioning”).
If a table fits almost entirely in main memory, the fastest way
to perform queries on it is to use hash indexes.
InnoDB has a mechanism that monitors index
searches made to the indexes defined for a table. If
InnoDB notices that queries could benefit
from building a hash index, it does so automatically.
The hash index is always built based on an existing B-tree index
on the table. InnoDB can build a hash index
on a prefix of any length of the key defined for the B-tree,
depending on the pattern of searches that
InnoDB observes for the B-tree index. A hash
index can be partial: It is not required that the whole B-tree
index is cached in the buffer pool. InnoDB
builds hash indexes on demand for those pages of the index that
are often accessed.
In a sense, InnoDB tailors itself through the
adaptive hash index mechanism to ample main memory, coming
closer to the architecture of main-memory databases.
The physical row structure for an InnoDB
table depends on the MySQL version and the optional
ROW_FORMAT option used when the table was
created. For InnoDB tables in MySQL 5.0.3 and
earlier, only the REDUNDANT row format was
available. For MySQL 5.0.3 and later, the default is to use the
COMPACT row format, but you can use the
REDUNDANT format to retain compatibility with
older versions of InnoDB tables. To check the
row format of an InnoDB table use
SHOW TABLE STATUS.
The compact row format decreases row storage space by about 20% at the cost of increasing CPU use for some operations. If your workload is a typical one that is limited by cache hit rates and disk speed, compact format is likely to be faster. If the workload is a rare case that is limited by CPU speed, compact format might be slower.
Rows in InnoDB tables that use
REDUNDANT row format have the following
characteristics:
Each index record contains a six-byte header. The header is used to link together consecutive records, and also in row-level locking.
Records in the clustered index contain fields for all user-defined columns. In addition, there is a six-byte transaction ID field and a seven-byte roll pointer field.
If no primary key was defined for a table, each clustered index record also contains a six-byte row ID field.
Each secondary index record also contains all the primary key fields defined for the clustered index key that are not in the secondary index.
A record contains a pointer to each field of the record. If the total length of the fields in a record is less than 128 bytes, the pointer is one byte; otherwise, two bytes. The array of these pointers is called the record directory. The area where these pointers point is called the data part of the record.
Internally,
InnoDBstores fixed-length character columns such asCHAR(10)in a fixed-length format. Before MySQL 5.0.3,InnoDBtruncates trailing spaces fromVARCHARcolumns.An SQL
NULLvalue reserves one or two bytes in the record directory. Besides that, an SQLNULLvalue reserves zero bytes in the data part of the record if stored in a variable length column. In a fixed-length column, it reserves the fixed length of the column in the data part of the record. Reserving the fixed space forNULLvalues enables an update of the column fromNULLto a non-NULLvalue to be done in place without causing fragmentation of the index page.
Rows in InnoDB tables that use
COMPACT row format have the following
characteristics:
Each index record contains a five-byte header that may be preceded by a variable-length header. The header is used to link together consecutive records, and also in row-level locking.
The variable-length part of the record header contains a bit vector for indicating
NULLcolumns. If the number of columns in the index that can beNULLisN, the bit vector occupies (N+7)/8 bytes. Columns that areNULLdo not occupy space other than the bit in this vector. The variable-length part of the header also contains the lengths of variable-length columns. Each length takes one or two bytes, depending on the maximum length of the column. If all columns in the index areNOT NULLand have a fixed length, the record header has no variable-length part.For each non-
NULLvariable-length field, the record header contains the length of the column in one or two bytes. Two bytes will only be needed if part of the column is stored externally in overflow pages or the maximum length exceeds 255 bytes and the actual length exceeds 127 bytes. For an externally stored column, the two-byte length indicates the length of the internally stored part plus the 20-byte pointer to the externally stored part. The internal part is 768 bytes, so the length is 768+20. The 20-byte pointer stores the true length of the column.The record header is followed by the data contents of the non-
NULLcolumns.Records in the clustered index contain fields for all user-defined columns. In addition, there is a six-byte transaction ID field and a seven-byte roll pointer field.
If no primary key was defined for a table, each clustered index record also contains a six-byte row ID field.
Each secondary index record also contains all the primary key fields defined for the clustered index key that are not in the secondary index. If any of these primary key fields are variable length, the record header for each secondary index will have a variable-length part to record their lengths, even if the secondary index is defined on fixed-length columns.
Internally,
InnoDBstores fixed-length, fixed-width character columns such asCHAR(10)in a fixed-length format. Before MySQL 5.0.3,InnoDBtruncates trailing spaces fromVARCHARcolumns.Internally,
InnoDBattempts to store UTF-8CHAR(columns inN)Nbytes by trimming trailing spaces. (WithREDUNDANTrow format, such columns occupy 3 ×Nbytes.) Reserving the minimum spaceNin many cases enables column updates to be done in place without causing fragmentation of the index page.
InnoDB uses simulated asynchronous disk I/O:
InnoDB creates a number of threads to take
care of I/O operations, such as read-ahead.
There are two read-ahead heuristics in
InnoDB:
In sequential read-ahead, if
InnoDBnotices that the access pattern to a segment in the tablespace is sequential, it posts in advance a batch of reads of database pages to the I/O system.In random read-ahead, if
InnoDBnotices that some area in a tablespace seems to be in the process of being fully read into the buffer pool, it posts the remaining reads to the I/O system.
InnoDB uses a novel file flush technique
called doublewrite. It adds safety to
recovery following an operating system crash or a power outage,
and improves performance on most varieties of Unix by reducing
the need for fsync() operations.
Doublewrite means that before writing pages to a data file,
InnoDB first writes them to a contiguous
tablespace area called the doublewrite buffer. Only after the
write and the flush to the doublewrite buffer has completed does
InnoDB write the pages to their proper
positions in the data file. If the operating system crashes in
the middle of a page write, InnoDB can later
find a good copy of the page from the doublewrite buffer during
recovery.
The data files that you define in the configuration file form
the InnoDB tablespace. The files are simply
concatenated to form the tablespace. There is no striping in
use. Currently, you cannot define where within the tablespace
your tables are allocated. However, in a newly created
tablespace, InnoDB allocates space starting
from the first data file.
The tablespace consists of database pages with a default size of
16KB. The pages are grouped into extents of size 1MB (64
consecutive pages). The “files” inside a tablespace
are called segments in
InnoDB. The term “rollback
segment” is somewhat confusing because it actually
contains many tablespace segments.
When a segment grows inside the tablespace,
InnoDB allocates the first 32 pages to it
individually. After that, InnoDB starts to
allocate whole extents to the segment. InnoDB
can add up to 4 extents at a time to a large segment to ensure
good sequentiality of data.
Two segments are allocated for each index in
InnoDB. One is for nonleaf nodes of the
B-tree, the other is for the leaf nodes. The idea here is to
achieve better sequentiality for the leaf nodes, which contain
the data.
Some pages in the tablespace contain bitmaps of other pages, and
therefore a few extents in an InnoDB
tablespace cannot be allocated to segments as a whole, but only
as individual pages.
When you ask for available free space in the tablespace by
issuing a SHOW TABLE STATUS
statement, InnoDB reports the extents that
are definitely free in the tablespace. InnoDB
always reserves some extents for cleanup and other internal
purposes; these reserved extents are not included in the free
space.
When you delete data from a table, InnoDB
contracts the corresponding B-tree indexes. Whether the freed
space becomes available for other users depends on whether the
pattern of deletes frees individual pages or extents to the
tablespace. Dropping a table or deleting all rows from it is
guaranteed to release the space to other users, but remember
that deleted rows are physically removed only in an (automatic)
purge operation after they are no longer needed for transaction
rollbacks or consistent reads. (See
Section 13.2.9, “InnoDB Multi-Versioning”.)
The maximum row length, except for variable-length columns
(VARBINARY,
VARCHAR,
BLOB and
TEXT), is slightly less than half
of a database page. That is, the maximum row length is about
8000 bytes. LONGBLOB and
LONGTEXT columns must be less
than 4GB, and the total row length, including
BLOB and
TEXT columns, must be less than
4GB.
If a row is less than half a page long, all of it is stored
locally within the page. If it exceeds half a page,
variable-length columns are chosen for external off-page storage
until the row fits within half a page. For a column chosen for
off-page storage, InnoDB stores the first 768
bytes locally in the row, and the rest externally into overflow
pages. Each such column has its own list of overflow pages. The
768-byte prefix is accompanied by a 20-byte value that stores
the true length of the column and points into the overflow list
where the rest of the value is stored.
To see information about the tablespace, use the Tablespace
Monitor. See Section 13.2.13.2, “SHOW ENGINE INNODB
STATUS and the InnoDB Monitors”.
If there are random insertions into or deletions from the indexes of a table, the indexes may become fragmented. Fragmentation means that the physical ordering of the index pages on the disk is not close to the index ordering of the records on the pages, or that there are many unused pages in the 64-page blocks that were allocated to the index.
One symptom of fragmentation is that a table takes more space
than it “should” take. How much that is exactly, is
difficult to determine. All InnoDB data and
indexes are stored in B-trees, and their fill factor may vary
from 50% to 100%. Another symptom of fragmentation is that a
table scan such as this takes more time than it
“should” take:
SELECT COUNT(*) FROM t WHERE a_non_indexed_column <> 12345;
(In the preceding query, we are “fooling” the SQL optimizer into scanning the clustered index rather than a secondary index.) Most disks can read 10MB/s to 50MB/s, which can be used to estimate how fast a table scan should be.
It can speed up index scans if you periodically perform a
“null” ALTER TABLE
operation, which causes MySQL to rebuild the table:
ALTER TABLE tbl_name ENGINE=INNODB
Another way to perform a defragmentation operation is to use mysqldump to dump the table to a text file, drop the table, and reload it from the dump file.
If the insertions into an index are always ascending and records
are deleted only from the end, the InnoDB
filespace management algorithm guarantees that fragmentation in
the index does not occur.
Error handling in InnoDB is not always the same
as specified in the SQL standard. According to the standard, any
error during an SQL statement should cause rollback of that
statement. InnoDB sometimes rolls back only
part of the statement, or the whole transaction. The following
items describe how InnoDB performs error
handling:
If you run out of file space in the tablespace, a MySQL
Table is fullerror occurs andInnoDBrolls back the SQL statement.A transaction deadlock causes
InnoDBto roll back the entire transaction. You should normally retry the whole transaction when this happens.A lock wait timeout causes
InnoDBto roll back only the single statement that was waiting for the lock and encountered the timeout. (Until MySQL 5.0.13InnoDBrolled back the entire transaction if a lock wait timeout happened. You can restore this behavior by starting the server with the--innodb_rollback_on_timeoutoption, available as of MySQL 5.0.32.) You should normally retry the statement if using the current behavior or the entire transaction if using the old behavior.Both deadlocks and lock wait timeouts are normal on busy servers and it is necessary for applications to be aware that they may happen and handle them by retrying. You can make them less likely by doing as little work as possible between the first change to data during a transaction and the commit, so the locks are held for the shortest possible time and for the smallest possible number of rows. Sometimes splitting work between different transactions may be practical and helpful.
When a transaction rollback occurs due to a deadlock or lock wait timeout, it cancels the effect of the statements within the transaction. But if the start-transaction statement was
START TRANSACTIONorBEGINstatement, rollback does not cancel that statement. Further SQL statements become part of the transaction until the occurrence ofCOMMIT,ROLLBACK, or some SQL statement that causes an implicit commit.A duplicate-key error rolls back the SQL statement, if you have not specified the
IGNOREoption in your statement.A
row too long errorrolls back the SQL statement.Other errors are mostly detected by the MySQL layer of code (above the
InnoDBstorage engine level), and they roll back the corresponding SQL statement. Locks are not released in a rollback of a single SQL statement.
During implicit rollbacks, as well as during the execution of an
explicit
ROLLBACK SQL
statement, SHOW PROCESSLIST
displays Rolling back in the
State column for the relevant connection.
The following is a nonexhaustive list of common
InnoDB-specific errors that you may
encounter, with information about why each occurs and how to
resolve the problem.
1005 (ER_CANT_CREATE_TABLE)Cannot create table. If the error message refers to error 150, table creation failed because a foreign key constraint was not correctly formed. If the error message refers to error –1, table creation probably failed because the table includes a column name that matched the name of an internal
InnoDBtable.1016 (ER_CANT_OPEN_FILE)Cannot find the
InnoDBtable from theInnoDBdata files, although the.frmfile for the table exists. See Section 13.2.13.4, “TroubleshootingInnoDBData Dictionary Operations”.1114 (ER_RECORD_FILE_FULL)InnoDBhas run out of free space in the tablespace. You should reconfigure the tablespace to add a new data file.1205 (ER_LOCK_WAIT_TIMEOUT)Lock wait timeout expired. Transaction was rolled back.
1213 (ER_LOCK_DEADLOCK)Transaction deadlock. You should rerun the transaction.
1216 (ER_NO_REFERENCED_ROW)You are trying to add a row but there is no parent row, and a foreign key constraint fails. You should add the parent row first.
1217 (ER_ROW_IS_REFERENCED)You are trying to delete a parent row that has children, and a foreign key constraint fails. You should delete the children first.
To print the meaning of an operating system error number, use the perror program that comes with the MySQL distribution.
The following table provides a list of some common Linux system error codes. For a more complete list, see Linux source code.
1 (EPERM)Operation not permitted
2 (ENOENT)No such file or directory
3 (ESRCH)No such process
4 (EINTR)Interrupted system call
5 (EIO)I/O error
6 (ENXIO)No such device or address
7 (E2BIG)Arg list too long
8 (ENOEXEC)Exec format error
9 (EBADF)Bad file number
10 (ECHILD)No child processes
11 (EAGAIN)Try again
12 (ENOMEM)Out of memory
13 (EACCES)Permission denied
14 (EFAULT)Bad address
15 (ENOTBLK)Block device required
16 (EBUSY)Device or resource busy
17 (EEXIST)File exists
18 (EXDEV)Cross-device link
19 (ENODEV)No such device
20 (ENOTDIR)Not a directory
21 (EISDIR)Is a directory
22 (EINVAL)Invalid argument
23 (ENFILE)File table overflow
24 (EMFILE)Too many open files
25 (ENOTTY)Inappropriate ioctl for device
26 (ETXTBSY)Text file busy
27 (EFBIG)File too large
28 (ENOSPC)No space left on device
29 (ESPIPE)Illegal seek
30 (EROFS)Read-only file system
31 (EMLINK)Too many links
The following table provides a list of some common Windows system error codes. For a complete list, see the Microsoft Web site.
1 (ERROR_INVALID_FUNCTION)Incorrect function.
2 (ERROR_FILE_NOT_FOUND)The system cannot find the file specified.
3 (ERROR_PATH_NOT_FOUND)The system cannot find the path specified.
4 (ERROR_TOO_MANY_OPEN_FILES)The system cannot open the file.
5 (ERROR_ACCESS_DENIED)Access is denied.
6 (ERROR_INVALID_HANDLE)The handle is invalid.
7 (ERROR_ARENA_TRASHED)The storage control blocks were destroyed.
8 (ERROR_NOT_ENOUGH_MEMORY)Not enough storage is available to process this command.
9 (ERROR_INVALID_BLOCK)The storage control block address is invalid.
10 (ERROR_BAD_ENVIRONMENT)The environment is incorrect.
11 (ERROR_BAD_FORMAT)An attempt was made to load a program with an incorrect format.
12 (ERROR_INVALID_ACCESS)The access code is invalid.
13 (ERROR_INVALID_DATA)The data is invalid.
14 (ERROR_OUTOFMEMORY)Not enough storage is available to complete this operation.
15 (ERROR_INVALID_DRIVE)The system cannot find the drive specified.
16 (ERROR_CURRENT_DIRECTORY)The directory cannot be removed.
17 (ERROR_NOT_SAME_DEVICE)The system cannot move the file to a different disk drive.
18 (ERROR_NO_MORE_FILES)There are no more files.
19 (ERROR_WRITE_PROTECT)The media is write protected.
20 (ERROR_BAD_UNIT)The system cannot find the device specified.
21 (ERROR_NOT_READY)The device is not ready.
22 (ERROR_BAD_COMMAND)The device does not recognize the command.
23 (ERROR_CRC)Data error (cyclic redundancy check).
24 (ERROR_BAD_LENGTH)The program issued a command but the command length is incorrect.
25 (ERROR_SEEK)The drive cannot locate a specific area or track on the disk.
26 (ERROR_NOT_DOS_DISK)The specified disk or diskette cannot be accessed.
27 (ERROR_SECTOR_NOT_FOUND)The drive cannot find the sector requested.
28 (ERROR_OUT_OF_PAPER)The printer is out of paper.
29 (ERROR_WRITE_FAULT)The system cannot write to the specified device.
30 (ERROR_READ_FAULT)The system cannot read from the specified device.
31 (ERROR_GEN_FAILURE)A device attached to the system is not functioning.
32 (ERROR_SHARING_VIOLATION)The process cannot access the file because it is being used by another process.
33 (ERROR_LOCK_VIOLATION)The process cannot access the file because another process has locked a portion of the file.
34 (ERROR_WRONG_DISK)The wrong diskette is in the drive. Insert %2 (Volume Serial Number: %3) into drive %1.
36 (ERROR_SHARING_BUFFER_EXCEEDED)Too many files opened for sharing.
38 (ERROR_HANDLE_EOF)Reached the end of the file.
39 (ERROR_HANDLE_DISK_FULL)The disk is full.
87 (ERROR_INVALID_PARAMETER)The parameter is incorrect.
112 (ERROR_DISK_FULL)The disk is full.
123 (ERROR_INVALID_NAME)The file name, directory name, or volume label syntax is incorrect.
1450 (ERROR_NO_SYSTEM_RESOURCES)Insufficient system resources exist to complete the requested service.
In
InnoDB, having a longPRIMARY KEYwastes a lot of disk space because its value must be stored with every secondary index record. (See Section 13.2.10, “InnoDBTable and Index Structures”.) Create anAUTO_INCREMENTcolumn as the primary key if your primary key is long.If you have
UNIQUEconstraints on secondary keys, you can speed up table imports by temporarily turning off the uniqueness checks during the import session:SET unique_checks=0;
... import operation ...SET unique_checks=1;For big tables, this saves a lot of disk I/O because
InnoDBcan use its insert buffer to write secondary index records in a batch. Be certain that the data contains no duplicate keys.If you have
FOREIGN KEYconstraints in your tables, you can speed up table imports by turning the foreign key checks off for the duration of the import session:SET foreign_key_checks=0;
... import operation ...SET foreign_key_checks=1;For big tables, this can save a lot of disk I/O.
If the Unix
toptool or the Windows Task Manager shows that the CPU usage percentage with your workload is less than 70%, your workload is probably disk-bound. Maybe you are making too many transaction commits, or the buffer pool is too small. Making the buffer pool bigger can help, but do not set it equal to more than 80% of physical memory.Wrap several modifications into a single transaction to reduce the number of flush operations.
InnoDBmust flush the log to disk at each transaction commit if that transaction made modifications to the database. The rotation speed of a disk is typically at most 167 revolutions/second, which constrains the number of commits to the same 167th of a second if the disk does not “fool” the operating system.If you can afford the loss of some of the latest committed transactions if a crash occurs, you can set the
innodb_flush_log_at_trx_commitparameter to 0.InnoDBtries to flush the log once per second anyway, although the flush is not guaranteed.Make your log files big, even as big as the buffer pool. When
InnoDBhas written the log files full, it must write the modified contents of the buffer pool to disk in a checkpoint. Small log files cause many unnecessary disk writes. The disadvantage of big log files is that the recovery time is longer.Make the log buffer quite large as well (on the order of 8MB).
Use the
VARCHARdata type instead ofCHARif you are storing variable-length strings or if the column may contain manyNULLvalues. ACHAR(column always takesN)Ncharacters to store data, even if the string is shorter or its value isNULL. Smaller tables fit better in the buffer pool and reduce disk I/O.When using
COMPACTrow format (the defaultInnoDBformat in MySQL 5.0) and variable-length character sets, such asutf8orsjis,CHAR(will occupy a variable amount of space, at leastN)Nbytes.In some versions of GNU/Linux and Unix, flushing files to disk with the Unix
fsync()call (whichInnoDBuses by default) and other similar methods is surprisingly slow. If you are dissatisfied with database write performance, you might try setting theinnodb_flush_methodparameter toO_DSYNC. TheO_DSYNCflush method seems to perform slower on most systems, but yours might not be one of them.When using the
InnoDBstorage engine on Solaris 10 for x86_64 architecture (AMD Opteron), it is important to mount any file systems used for storingInnoDB-related files using theforcedirectiooption. (The default on Solaris 10/x86_64 is not to use this option.) Failure to useforcedirectiocauses a serious degradation ofInnoDB's speed and performance on this platform.When using the
InnoDBstorage engine with a largeinnodb_buffer_pool_sizevalue on any release of Solaris 2.6 and up and any platform (sparc/x86/x64/amd64), a significant performance gain might be achieved by placingInnoDBdata files and log files on raw devices or on a separate direct I/O UFS file system (using theforcedirectiomount option; seemount_ufs(1M)). Users of the Veritas file system VxFS should use theconvosync=directmount option. You are advised to perform tests with and without raw partitions or direct I/O file systems to verify whether performance is improved on your system.Other MySQL data files, such as those for
MyISAMtables, should not be placed on a direct I/O file system. Executables or libraries must not be placed on a direct I/O file system.When importing data into
InnoDB, make sure that MySQL does not have autocommit mode enabled because that requires a log flush to disk for every insert. To disable autocommit during your import operation, surround it withSET autocommitandCOMMITstatements:SET autocommit=0;
... SQL import statements ...COMMIT;If you use the mysqldump option
--opt, you get dump files that are fast to import into anInnoDBtable, even without wrapping them with theSET autocommitandCOMMITstatements.Beware of big rollbacks of mass inserts:
InnoDBuses the insert buffer to save disk I/O in inserts, but no such mechanism is used in a corresponding rollback. A disk-bound rollback can take 30 times as long to perform as the corresponding insert. Killing the database process does not help because the rollback starts again on server startup. The only way to get rid of a runaway rollback is to increase the buffer pool so that the rollback becomes CPU-bound and runs fast, or to use a special procedure. See Section 13.2.6.2, “ForcingInnoDBRecovery”.Beware also of other big disk-bound operations. Use
DROP TABLEandCREATE TABLEto empty a table, notDELETE FROM.tbl_nameUse the multiple-row
INSERTsyntax to reduce communication overhead between the client and the server if you need to insert many rows:INSERT INTO yourtable VALUES (1,2), (5,5), ...;
This tip is valid for inserts into any table, not just
InnoDBtables.If you often have recurring queries for tables that are not updated frequently, enable the query cache:
[mysqld] query_cache_type = 1 query_cache_size = 10M
Unlike
MyISAM,InnoDBdoes not store an index cardinality value in its tables. Instead,InnoDBcomputes a cardinality for a table the first time it accesses it after startup. With a large number of tables, this might take significant time. It is the initial table open operation that is important, so to “warm up” a table for later use, access it immediately after startup by issuing a statement such asSELECT 1 FROM.tbl_nameLIMIT 1
MySQL Enterprise For optimization recommendations geared to your specific circumstances subscribe to the MySQL Enterprise Monitor. For more information, see http://www.mysql.com/products/enterprise/advisors.html.
InnoDB Monitors provide information about the
InnoDB internal state. This information is
useful for performance tuning. Each Monitor can be enabled by
creating a table with a special name, which causes
InnoDB to write Monitor output periodically.
Also, output for the standard InnoDB Monitor
is available on demand via the
SHOW ENGINE INNODB
STATUS SQL statement.
There are several types of InnoDB Monitors:
The standard
InnoDBMonitor displays the following types of information:Table and record locks held by each active transaction
Lock waits of a transactions
Semaphore waits of threads
Pending file I/O requests
Buffer pool statistics
Purge and insert buffer merge activity of the main
InnoDBthread
For a discussion of
InnoDBlock modes, see Section 13.2.8.1, “InnoDBLock Modes”.To enable the standard
InnoDBMonitor for periodic output, create a table namedinnodb_monitor. To obtain Monitor output on demand, use theSHOW ENGINE INNODB STATUSSQL statement to fetch the output to your client program. If you are using the mysql interactive client, the output is more readable if you replace the usual semicolon statement terminator with\G:mysql>
SHOW ENGINE INNODB STATUS\GThe
InnoDBLock Monitor is like the standard Monitor but also provides extensive lock information. To enable this Monitor for periodic output, create a table namedinnodb_lock_monitor.The
InnoDBTablespace Monitor prints a list of file segments in the shared tablespace and validates the tablespace allocation data structures. To enable this Monitor for periodic output, create a table namedinnodb_tablespace_monitor.The
InnoDBTable Monitor prints the contents of theInnoDBinternal data dictionary. To enable this Monitor for periodic output, create a table namedinnodb_table_monitor.
To enable an InnoDB Monitor for periodic
output, use a CREATE TABLE statement to
create the table associated with the Monitor. For example, to
enable the standard InnoDB Monitor, create
the innodb_monitor table:
CREATE TABLE innodb_monitor (a INT) ENGINE=INNODB;
To stop the Monitor, drop the table:
DROP TABLE innodb_monitor;
The CREATE TABLE syntax is just a
way to pass a command to the InnoDB engine
through MySQL's SQL parser: The only things that matter are the
table name innodb_monitor and that it be an
InnoDB table. The structure of the table is
not relevant at all for the InnoDB Monitor.
If you shut down the server, the Monitor does not restart
automatically when you restart the server. You must drop the
Monitor table and issue a new CREATE
TABLE statement to start the Monitor. (This syntax may
change in a future release.)
When you enable InnoDB Monitors for periodic
output, InnoDB writes their output to the
mysqld server standard error output
(stderr). In this case, no output is sent to
clients. When switched on, InnoDB Monitors
print data about every 15 seconds. Server output usually is
directed to the error log (see Section 5.2.1, “The Error Log”).
This data is useful in performance tuning. On Windows, you must
start the server from a command prompt in a console window with
the --console option if you want
to direct the output to the window rather than to the error log.
InnoDB sends diagnostic output to
stderr or to files rather than to
stdout or fixed-size memory buffers, to avoid
potential buffer overflows. As a side effect, the output of
SHOW ENGINE INNODB
STATUS is written to a status file in the MySQL data
directory every fifteen seconds. The name of the file is
innodb_status.,
where pidpid is the server process ID.
InnoDB removes the file for a normal
shutdown. If abnormal shutdowns have occurred, instances of
these status files may be present and must be removed manually.
Before removing them, you might want to examine them to see
whether they contain useful information about the cause of
abnormal shutdowns. The
innodb_status.
file is created only if the configuration option
pidinnodb_status_file=1 is set.
InnoDB Monitors should be enabled only when
you actually want to see Monitor information because output
generation does result in some performance decrement. Also, if
you enable monitor output by creating the associated table, your
error log may become quite large if you forget to remove the
table later.
For additional information about InnoDB
monitors, see the following resources:
Mark Leith: InnoDB Table and Tablespace Monitors
MySQL Performance Blog: SHOW INNODB STATUS walk through
Each monitor begins with a header containing a timestamp and the monitor name. For example:
================================================ 090407 12:06:19 INNODB TABLESPACE MONITOR OUTPUT ================================================
The header for the standard Monitor (INNODB MONITOR
OUTPUT) is also used for the Lock Monitor because the
latter produces the same output with the addition of extra lock
information.
The following sections describe the output for each Monitor.
The Lock Monitor is the same as the standard Monitor except
that it includes additional lock information. Enabling either
monitor for periodic output by creating the associated
InnoDB table turns on the same output
stream, but the stream includes the extra information if the
Lock Monitor is enabled. For example, if you create the
innodb_monitor and
innodb_lock_monitor tables, that turns on a
single output stream. The stream includes extra lock
information until you disable the Lock Monitor by removing the
innodb_lock_monitor table.
Example InnoDB Monitor output:
mysql> SHOW ENGINE INNODB STATUS\G
*************************** 1. row ***************************
Status:
=====================================
030709 13:00:59 INNODB MONITOR OUTPUT
=====================================
Per second averages calculated from the last 18 seconds
----------
SEMAPHORES
----------
OS WAIT ARRAY INFO: reservation count 413452, signal count 378357
--Thread 32782 has waited at btr0sea.c line 1477 for 0.00 seconds the
semaphore: X-lock on RW-latch at 41a28668 created in file btr0sea.c line 135
a writer (thread id 32782) has reserved it in mode wait exclusive
number of readers 1, waiters flag 1
Last time read locked in file btr0sea.c line 731
Last time write locked in file btr0sea.c line 1347
Mutex spin waits 0, rounds 0, OS waits 0
RW-shared spins 108462, OS waits 37964; RW-excl spins 681824, OS waits
375485
------------------------
LATEST FOREIGN KEY ERROR
------------------------
030709 13:00:59 Transaction:
TRANSACTION 0 290328284, ACTIVE 0 sec, process no 3195, OS thread id 34831
inserting
15 lock struct(s), heap size 2496, undo log entries 9
MySQL thread id 25, query id 4668733 localhost heikki update
insert into ibtest11a (D, B, C) values (5, 'khDk' ,'khDk')
Foreign key constraint fails for table test/ibtest11a:
,
CONSTRAINT `0_219242` FOREIGN KEY (`A`, `D`) REFERENCES `ibtest11b` (`A`,
`D`) ON DELETE CASCADE ON UPDATE CASCADE
Trying to add in child table, in index PRIMARY tuple:
0: len 4; hex 80000101; asc ....;; 1: len 4; hex 80000005; asc ....;; 2:
len 4; hex 6b68446b; asc khDk;; 3: len 6; hex 0000114e0edc; asc ...N..;; 4:
len 7; hex 00000000c3e0a7; asc .......;; 5: len 4; hex 6b68446b; asc khDk;;
But in parent table test/ibtest11b, in index PRIMARY,
the closest match we can find is record:
RECORD: info bits 0 0: len 4; hex 8000015b; asc ...[;; 1: len 4; hex
80000005; asc ....;; 2: len 3; hex 6b6864; asc khd;; 3: len 6; hex
0000111ef3eb; asc ......;; 4: len 7; hex 800001001e0084; asc .......;; 5:
len 3; hex 6b6864; asc khd;;
------------------------
LATEST DETECTED DEADLOCK
------------------------
030709 12:59:58
*** (1) TRANSACTION:
TRANSACTION 0 290252780, ACTIVE 1 sec, process no 3185, OS thread id 30733
inserting
LOCK WAIT 3 lock struct(s), heap size 320, undo log entries 146
MySQL thread id 21, query id 4553379 localhost heikki update
INSERT INTO alex1 VALUES(86, 86, 794,'aA35818','bb','c79166','d4766t',
'e187358f','g84586','h794',date_format('2001-04-03 12:54:22','%Y-%m-%d
%H:%i'),7
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 0 page no 48310 n bits 568 table test/alex1 index
symbole trx id 0 290252780 lock mode S waiting
Record lock, heap no 324 RECORD: info bits 0 0: len 7; hex 61613335383138;
asc aa35818;; 1:
*** (2) TRANSACTION:
TRANSACTION 0 290251546, ACTIVE 2 sec, process no 3190, OS thread id 32782
inserting
130 lock struct(s), heap size 11584, undo log entries 437
MySQL thread id 23, query id 4554396 localhost heikki update
REPLACE INTO alex1 VALUES(NULL, 32, NULL,'aa3572','','c3572','d6012t','',
NULL,'h396', NULL, NULL, 7.31,7.31,7.31,200)
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 0 page no 48310 n bits 568 table test/alex1 index
symbole trx id 0 290251546 lock_mode X locks rec but not gap
Record lock, heap no 324 RECORD: info bits 0 0: len 7; hex 61613335383138;
asc aa35818;; 1:
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 0 page no 48310 n bits 568 table test/alex1 index
symbole trx id 0 290251546 lock_mode X locks gap before rec insert intention
waiting
Record lock, heap no 82 RECORD: info bits 0 0: len 7; hex 61613335373230;
asc aa35720;; 1:
*** WE ROLL BACK TRANSACTION (1)
------------
TRANSACTIONS
------------
Trx id counter 0 290328385
Purge done for trx's n:o < 0 290315608 undo n:o < 0 17
Total number of lock structs in row lock hash table 70
LIST OF TRANSACTIONS FOR EACH SESSION:
---TRANSACTION 0 0, not started, process no 3491, OS thread id 42002
MySQL thread id 32, query id 4668737 localhost heikki
show innodb status
---TRANSACTION 0 290328384, ACTIVE 0 sec, process no 3205, OS thread id
38929 inserting
1 lock struct(s), heap size 320
MySQL thread id 29, query id 4668736 localhost heikki update
insert into speedc values (1519229,1, 'hgjhjgghggjgjgjgjgjggjgjgjgjgjgggjgjg
jlhhgghggggghhjhghgggggghjhghghghghghhhhghghghjhhjghjghjkghjghjghjghjfhjfh
---TRANSACTION 0 290328383, ACTIVE 0 sec, process no 3180, OS thread id
28684 committing
1 lock struct(s), heap size 320, undo log entries 1
MySQL thread id 19, query id 4668734 localhost heikki update
insert into speedcm values (1603393,1, 'hgjhjgghggjgjgjgjgjggjgjgjgjgjgggjgj
gjlhhgghggggghhjhghgggggghjhghghghghghhhhghghghjhhjghjghjkghjghjghjghjfhjf
---TRANSACTION 0 290328327, ACTIVE 0 sec, process no 3200, OS thread id
36880 starting index read
LOCK WAIT 2 lock struct(s), heap size 320
MySQL thread id 27, query id 4668644 localhost heikki Searching rows for
update
update ibtest11a set B = 'kHdkkkk' where A = 89572
------- TRX HAS BEEN WAITING 0 SEC FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 0 page no 65556 n bits 232 table test/ibtest11a index
PRIMARY trx id 0 290328327 lock_mode X waiting
Record lock, heap no 1 RECORD: info bits 0 0: len 9; hex 73757072656d756d00;
asc supremum.;;
------------------
---TRANSACTION 0 290328284, ACTIVE 0 sec, process no 3195, OS thread id
34831 rollback of SQL statement
ROLLING BACK 14 lock struct(s), heap size 2496, undo log entries 9
MySQL thread id 25, query id 4668733 localhost heikki update
insert into ibtest11a (D, B, C) values (5, 'khDk' ,'khDk')
---TRANSACTION 0 290327208, ACTIVE 1 sec, process no 3190, OS thread id
32782
58 lock struct(s), heap size 5504, undo log entries 159
MySQL thread id 23, query id 4668732 localhost heikki update
REPLACE INTO alex1 VALUES(86, 46, 538,'aa95666','bb','c95666','d9486t',
'e200498f','g86814','h538',date_format('2001-04-03 12:54:22','%Y-%m-%d
%H:%i'),
---TRANSACTION 0 290323325, ACTIVE 3 sec, process no 3185, OS thread id
30733 inserting
4 lock struct(s), heap size 1024, undo log entries 165
MySQL thread id 21, query id 4668735 localhost heikki update
INSERT INTO alex1 VALUES(NULL, 49, NULL,'aa42837','','c56319','d1719t','',
NULL,'h321', NULL, NULL, 7.31,7.31,7.31,200)
--------
FILE I/O
--------
I/O thread 0 state: waiting for i/o request (insert buffer thread)
I/O thread 1 state: waiting for i/o request (log thread)
I/O thread 2 state: waiting for i/o request (read thread)
I/O thread 3 state: waiting for i/o request (write thread)
Pending normal aio reads: 0, aio writes: 0,
ibuf aio reads: 0, log i/o's: 0, sync i/o's: 0
Pending flushes (fsync) log: 0; buffer pool: 0
151671 OS file reads, 94747 OS file writes, 8750 OS fsyncs
25.44 reads/s, 18494 avg bytes/read, 17.55 writes/s, 2.33 fsyncs/s
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf for space 0: size 1, free list len 19, seg size 21,
85004 inserts, 85004 merged recs, 26669 merges
Hash table size 207619, used cells 14461, node heap has 16 buffer(s)
1877.67 hash searches/s, 5121.10 non-hash searches/s
---
LOG
---
Log sequence number 18 1212842764
Log flushed up to 18 1212665295
Last checkpoint at 18 1135877290
0 pending log writes, 0 pending chkp writes
4341 log i/o's done, 1.22 log i/o's/second
----------------------
BUFFER POOL AND MEMORY
----------------------
Total memory allocated 84966343; in additional pool allocated 1402624
Buffer pool size 3200
Free buffers 110
Database pages 3074
Modified db pages 2674
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages read 171380, created 51968, written 194688
28.72 reads/s, 20.72 creates/s, 47.55 writes/s
Buffer pool hit rate 999 / 1000
--------------
ROW OPERATIONS
--------------
0 queries inside InnoDB, 0 queries in queue
Main thread process no. 3004, id 7176, state: purging
Number of rows inserted 3738558, updated 127415, deleted 33707, read 755779
1586.13 inserts/s, 50.89 updates/s, 28.44 deletes/s, 107.88 reads/s
----------------------------
END OF INNODB MONITOR OUTPUT
============================
InnoDB Monitor output is limited to 64,000
bytes when produced via the
SHOW ENGINE
INNODB STATUS statement. This limit does not apply
to output written to the server's error output.
Some notes on the output sections:
SEMAPHORESThis section reports threads waiting for a semaphore and statistics on how many times threads have needed a spin or a wait on a mutex or a rw-lock semaphore. A large number of threads waiting for semaphores may be a result of disk I/O, or contention problems inside
InnoDB. Contention can be due to heavy parallelism of queries or problems in operating system thread scheduling. Setting theinnodb_thread_concurrencysystem variable smaller than the default value might help in such situations.LATEST FOREIGN KEY ERRORThis section provides information about the most recent foreign key constraint error. It is not present if no such error has occurred. The contents include the statement that failed as well as information about the constraint that failed and the referenced and referencing tables.
LATEST DETECTED DEADLOCKThis section provides information about the most recent deadlock. It is not present if no deadlock has occurred. The contents show which transactions are involved, the statement each was attempting to execute, the locks they have and need, and which transaction
InnoDBdecided to roll back to break the deadlock. The lock modes reported in this section are explained in Section 13.2.8.1, “InnoDBLock Modes”.TRANSACTIONSIf this section reports lock waits, your applications might have lock contention. The output can also help to trace the reasons for transaction deadlocks.
FILE I/OThis section provides information about threads that
InnoDBuses to perform various types of I/O. The first few of these are dedicated to generalInnoDBprocessing. The contents also display information for pending I/O operations and statistics for I/O performance.On Unix, the number of threads is always 4. On Windows, the number depends on the setting of the
innodb_file_io_threadssystem variable.INSERT BUFFER AND ADAPTIVE HASH INDEXThis section shows the status of the
InnoDBinsert buffer and adaptive hash index. (See Section 13.2.10.3, “Insert Buffering”, and Section 13.2.10.4, “Adaptive Hash Indexes”.) The contents include the number of operations performed for each, plus statistics for hash index performance.LOGThis section displays information about the
InnoDBlog. The contents include the current log sequence number, how far the log has been flushed to disk, and the position at whichInnoDBlast took a checkpoint. (See Section 13.2.6.3, “InnoDBCheckpoints”.) The section also displays information about pending writes and write performance statistics.BUFFER POOL AND MEMORYThis section gives you statistics on pages read and written. You can calculate from these numbers how many data file I/O operations your queries currently are doing.
ROW OPERATIONSThis section shows what the main thread is doing, including the number and performance rate for each type of row operation.
The InnoDB Tablespace Monitor prints
information about the file segments in the shared tablespace
and validates the tablespace allocation data structures. If
you use individual tablespaces by enabling
innodb_file_per_table, the Tablespace
Monitor does not describe those tablespaces.
Example InnoDB Tablespace Monitor output:
================================================ 090408 21:28:09 INNODB TABLESPACE MONITOR OUTPUT ================================================ FILE SPACE INFO: id 0 size 13440, free limit 3136, free extents 28 not full frag extents 2: used pages 78, full frag extents 3 first seg id not used 0 23845 SEGMENT id 0 1 space 0; page 2; res 96 used 46; full ext 0 fragm pages 32; free extents 0; not full extents 1: pages 14 SEGMENT id 0 2 space 0; page 2; res 1 used 1; full ext 0 fragm pages 1; free extents 0; not full extents 0: pages 0 SEGMENT id 0 3 space 0; page 2; res 1 used 1; full ext 0 fragm pages 1; free extents 0; not full extents 0: pages 0 ... SEGMENT id 0 15 space 0; page 2; res 160 used 160; full ext 2 fragm pages 32; free extents 0; not full extents 0: pages 0 SEGMENT id 0 488 space 0; page 2; res 1 used 1; full ext 0 fragm pages 1; free extents 0; not full extents 0: pages 0 SEGMENT id 0 17 space 0; page 2; res 1 used 1; full ext 0 fragm pages 1; free extents 0; not full extents 0: pages 0 ... SEGMENT id 0 171 space 0; page 2; res 592 used 481; full ext 7 fragm pages 16; free extents 0; not full extents 2: pages 17 SEGMENT id 0 172 space 0; page 2; res 1 used 1; full ext 0 fragm pages 1; free extents 0; not full extents 0: pages 0 SEGMENT id 0 173 space 0; page 2; res 96 used 44; full ext 0 fragm pages 32; free extents 0; not full extents 1: pages 12 ... SEGMENT id 0 601 space 0; page 2; res 1 used 1; full ext 0 fragm pages 1; free extents 0; not full extents 0: pages 0 NUMBER of file segments: 73 Validating tablespace Validation ok --------------------------------------- END OF INNODB TABLESPACE MONITOR OUTPUT =======================================
The Tablespace Monitor output includes information about the shared tablespace as a whole, followed by a list containing a breakdown for each segment within the tablespace.
The tablespace consists of database pages with a default size of 16KB. The pages are grouped into extents of size 1MB (64 consecutive pages).
The initial part of the output that displays overall tablespace information has this format:
FILE SPACE INFO: id 0 size 13440, free limit 3136, free extents 28 not full frag extents 2: used pages 78, full frag extents 3 first seg id not used 0 23845
Overall tablespace information includes these values:
id: The tablespace ID. A value of 0 refers to the shared tablespace.size: The current tablespace size in pages.free limit: The minimum page number for which the free list has not been initialized. Pages at or above this limit are free.free extents: The number of free extents.not full frag extents,used pages: The number of fragment extents that are not completely filled, and the number of pages in those extents that have been allocated.full frag extents: The number of completely full fragment extents.first seg id not used: The first unused segment ID.
Individual segment information has this format:
SEGMENT id 0 15 space 0; page 2; res 160 used 160; full ext 2 fragm pages 32; free extents 0; not full extents 0: pages 0
Segment information includes these values:
id: The segment ID.
space, page: The
tablespace number and page within the tablespace where the
segment “inode” is located. A tablespace number
of 0 indicates the shared tablespace.
InnoDB uses inodes to keep track of
segments in the tablespace. The other fields displayed for a
segment (id, res, and so
forth) are derived from information in the inode.
res: The number of pages allocated
(reserved) for the segment.
used: The number of allocated pages in use
by the segment.
full ext: The number of extents allocated
for the segment that are completely used.
fragm pages: The number of initial pages
that have been allocated to the segment.
free extents: The number of extents
allocated for the segment that are completely unused.
not full extents: The number of extents
allocated for the segment that are partially used.
pages: The number of pages used within the
not-full extents.
When a segment grows, it starts as a single page, and
InnoDB allocates the first pages for it
individually, up to 32 pages (this is the fragm
pages value). After that, InnoDB
allocates complete 64-page extents. InnoDB
can add up to 4 extents at a time to a large segment to ensure
good sequentiality of data.
For the example segment shown earlier, it has 32 fragment pages, plus 2 full extents (64 pages each), for a total of 160 pages used out of 160 pages allocated. The following segment has 32 fragment pages and one partially full extent using 14 pages for a total of 46 pages used out of 96 pages allocated:
SEGMENT id 0 1 space 0; page 2; res 96 used 46; full ext 0 fragm pages 32; free extents 0; not full extents 1: pages 14
It is possible for a segment that has extents allocated to it
to have a fragm pages value less than 32 if
some of the individual pages have been deallocated subsequent
to extent allocation.
The InnoDB Table Monitor prints the
contents of the InnoDB internal data
dictionary.
The output contains one section per table. The
SYS_FOREIGN and
SYS_FOREIGN_COLS sections are for internal
data dictionary tables that maintain information about foreign
keys. There are also sections for the Table Monitor table and
each user-created InnoDB table. Suppose
that the following two tables have been created in the
test database:
CREATE TABLE parent
(
par_id INT NOT NULL,
fname CHAR(20),
lname CHAR(20),
PRIMARY KEY (par_id),
UNIQUE INDEX (lname, fname)
) ENGINE = INNODB;
CREATE TABLE child
(
par_id INT NOT NULL,
child_id INT NOT NULL,
name VARCHAR(40),
birth DATE,
weight DECIMAL(10,2),
misc_info VARCHAR(255),
last_update TIMESTAMP,
PRIMARY KEY (par_id, child_id),
INDEX (name),
FOREIGN KEY (par_id) REFERENCES parent (par_id)
ON DELETE CASCADE
ON UPDATE CASCADE
) ENGINE = INNODB;
Then the Table Monitor output will look something like this (reformatted slightly):
===========================================
090420 12:05:26 INNODB TABLE MONITOR OUTPUT
===========================================
--------------------------------------
TABLE: name SYS_FOREIGN, id 0 11, columns 8, indexes 3, appr.rows 1
COLUMNS: ID: DATA_VARCHAR DATA_ENGLISH len 0 prec 0;
FOR_NAME: DATA_VARCHAR DATA_ENGLISH len 0 prec 0;
REF_NAME: DATA_VARCHAR DATA_ENGLISH len 0 prec 0;
N_COLS: DATA_INT len 4 prec 0;
DB_ROW_ID: DATA_SYS prtype 256 len 6 prec 0;
DB_TRX_ID: DATA_SYS prtype 257 len 6 prec 0;
DB_ROLL_PTR: DATA_SYS prtype 258 len 7 prec 0;
INDEX: name ID_IND, id 0 11, fields 1/6, type 3
root page 46, appr.key vals 1, leaf pages 1, size pages 1
FIELDS: ID DB_TRX_ID DB_ROLL_PTR FOR_NAME REF_NAME N_COLS
INDEX: name FOR_IND, id 0 12, fields 1/2, type 0
root page 47, appr.key vals 1, leaf pages 1, size pages 1
FIELDS: FOR_NAME ID
INDEX: name REF_IND, id 0 13, fields 1/2, type 0
root page 48, appr.key vals 1, leaf pages 1, size pages 1
FIELDS: REF_NAME ID
--------------------------------------
TABLE: name SYS_FOREIGN_COLS, id 0 12, columns 8, indexes 1, appr.rows 1
COLUMNS: ID: DATA_VARCHAR DATA_ENGLISH len 0 prec 0;
POS: DATA_INT len 4 prec 0;
FOR_COL_NAME: DATA_VARCHAR DATA_ENGLISH len 0 prec 0;
REF_COL_NAME: DATA_VARCHAR DATA_ENGLISH len 0 prec 0;
DB_ROW_ID: DATA_SYS prtype 256 len 6 prec 0;
DB_TRX_ID: DATA_SYS prtype 257 len 6 prec 0;
DB_ROLL_PTR: DATA_SYS prtype 258 len 7 prec 0;
INDEX: name ID_IND, id 0 14, fields 2/6, type 3
root page 49, appr.key vals 1, leaf pages 1, size pages 1
FIELDS: ID POS DB_TRX_ID DB_ROLL_PTR FOR_COL_NAME REF_COL_NAME
--------------------------------------
TABLE: name test/child, id 0 14, columns 11, indexes 2, appr.rows 210
COLUMNS: par_id: DATA_INT len 4 prec 0;
child_id: DATA_INT len 4 prec 0;
name: DATA_VARCHAR prtype 524303 len 40 prec 0;
birth: DATA_INT len 3 prec 0;
weight: type 3 len 5 prec 0;
misc_info: DATA_VARCHAR prtype 524303 len 255 prec 0;
last_update: DATA_INT len 4 prec 0;
DB_ROW_ID: DATA_SYS prtype 256 len 6 prec 0;
DB_TRX_ID: DATA_SYS prtype 257 len 6 prec 0;
DB_ROLL_PTR: DATA_SYS prtype 258 len 7 prec 0;
INDEX: name PRIMARY, id 0 17, fields 2/9, type 3
root page 52, appr.key vals 210, leaf pages 1, size pages 1
FIELDS: par_id child_id DB_TRX_ID DB_ROLL_PTR name birth weight misc_info last_update
INDEX: name name, id 0 18, fields 1/3, type 0
root page 53, appr.key vals 1, leaf pages 1, size pages 1
FIELDS: name par_id child_id
FOREIGN KEY CONSTRAINT test/child_ibfk_1: test/child ( par_id )
REFERENCES test/parent ( par_id )
--------------------------------------
TABLE: name test/innodb_table_monitor, id 0 15, columns 5, indexes 1, appr.rows 0
COLUMNS: i: DATA_INT len 4 prec 0;
DB_ROW_ID: DATA_SYS prtype 256 len 6 prec 0;
DB_TRX_ID: DATA_SYS prtype 257 len 6 prec 0;
DB_ROLL_PTR: DATA_SYS prtype 258 len 7 prec 0;
INDEX: name GEN_CLUST_INDEX, id 0 19, fields 0/4, type 1
root page 54, appr.key vals 0, leaf pages 1, size pages 1
FIELDS: DB_ROW_ID DB_TRX_ID DB_ROLL_PTR i
--------------------------------------
TABLE: name test/parent, id 0 13, columns 7, indexes 2, appr.rows 299
COLUMNS: par_id: DATA_INT len 4 prec 0;
fname: DATA_CHAR prtype 524542 len 20 prec 0;
lname: DATA_CHAR prtype 524542 len 20 prec 0;
DB_ROW_ID: DATA_SYS prtype 256 len 6 prec 0;
DB_TRX_ID: DATA_SYS prtype 257 len 6 prec 0;
DB_ROLL_PTR: DATA_SYS prtype 258 len 7 prec 0;
INDEX: name PRIMARY, id 0 15, fields 1/5, type 3
root page 50, appr.key vals 299, leaf pages 2, size pages 3
FIELDS: par_id DB_TRX_ID DB_ROLL_PTR fname lname
INDEX: name lname, id 0 16, fields 2/3, type 2
root page 51, appr.key vals 300, leaf pages 1, size pages 1
FIELDS: lname fname par_id
FOREIGN KEY CONSTRAINT test/child_ibfk_1: test/child ( par_id )
REFERENCES test/parent ( par_id )
-----------------------------------
END OF INNODB TABLE MONITOR OUTPUT
==================================
For each table, Table Monitor output contains a section that displays general information about the table and specific information about its columns, indexes, and foreign keys.
The general information for each table includes the table name
(in
db_name/tbl_name
The COLUMNS part of a table section lists
each column in the table. Information for each column
indicates its name and data type characteristics. Some
internal columns are added by InnoDB, such
as DB_ROW_ID (row ID),
DB_TRX_ID (transaction ID), and
DB_ROLL_PTR (a pointer to the rollback/undo
data).
DATA_: These symbols indicate the data type. There may be multiplexxxDATA_symbols for a given column.xxxprtype: The column's “precise” type. This field includes information such as the column data type, character set code, nullability, signedness, and whether it is a binary string. This field is described in theinnobase/include/data0type.hsource file.len: The column length in bytes.prec: The precision of the type.
Each INDEX part of the table section
provides the name and characteristics of one table index:
name: The index name. If the name isPRIMARY, the index is a primary key. If the name isGEN_CLUST_INDEX, the index is the clustered index that is created automatically if the table definition doesn't include a primary key or non-NULLunique index. See Section 13.2.10.1, “Clustered and Secondary Indexes”.id: The index ID.fields: The number of fields in the index, as a value inm/nmis the number of user-defined columns; that is, the number of columns you would see in the index definition in aCREATE TABLEstatement.nis the total number of index columns, including those added internally. For the clustered index, the total includes the other columns in the table definition, plus any columns added internally. For a secondary index, the total includes the columns from the primary key that are not part of the secondary index.
type: The index type. This is a bit field. For example, 1 indicates a clustered index and 2 indicates a unique index, so a clustered index (which always contains unique values), will have atypevalue of 3. An index with atypevalue of 0 is neither clustered nor unique. The flag values are defined in theinnobase/include/dict0mem.hsource file.root page: The index root page number.appr. key vals: The approximate index cardinality.leaf pages: The approximate number of leaf pages in the index.size pages: The approximate total number of pages in the index.FIELDS: The names of the fields in the index. For a clustered index that was generated automatically, the field list begins with the internalDB_ROW_ID(row ID) field.DB_TRX_IDandDB_ROLL_PTRare always added internally to the clustered index, following the fields that comprise the primary key. For a secondary index, the final fields are those from the primary key that are not part of the secondary index.
The end of the table section lists the FOREIGN
KEY definitions that apply to the table. This
information appears whether the table is a referencing or
referenced table.
The following general guidelines apply to troubleshooting
InnoDB problems:
When an operation fails or you suspect a bug, you should look at the MySQL server error log (see Section 5.2.1, “The Error Log”).
Issues relating to the
InnoDBdata dictionary include failedCREATE TABLEstatements (orphaned table files), inability to open.InnoDBfiles, and system cannot find the path specified errors. For information about these sorts of problems and errors, see Section 13.2.13.4, “TroubleshootingInnoDBData Dictionary Operations”.When troubleshooting, it is usually best to run the MySQL server from the command prompt, rather than through mysqld_safe or as a Windows service. You can then see what mysqld prints to the console, and so have a better grasp of what is going on. On Windows, start mysqld with the
--consoleoption to direct the output to the console window.Use the
InnoDBMonitors to obtain information about a problem (see Section 13.2.13.2, “SHOW ENGINE INNODB STATUSand theInnoDBMonitors”). If the problem is performance-related, or your server appears to be hung, you should use the standard Monitor to print information about the internal state ofInnoDB. If the problem is with locks, use the Lock Monitor. If the problem is in creation of tables or other data dictionary operations, use the Table Monitor to print the contents of theInnoDBinternal data dictionary. To see tablespace information use the Tablespace Monitor.If you suspect that a table is corrupt, run
CHECK TABLEon that table.
MySQL Enterprise The MySQL Enterprise Monitor provides a number of advisors specifically designed for monitoring InnoDB tables. In some cases, these advisors can anticipate potential problems. For more information, see http://www.mysql.com/products/enterprise/advisors.html.
A specific issue with tables is that the MySQL server keeps data
dictionary information in .frm files it
stores in the database directories, whereas
InnoDB also stores the information into its
own data dictionary inside the tablespace files. If you move
.frm files around, or if the server crashes
in the middle of a data dictionary operation, the locations of
the .frm files may end up out of synchrony
with the locations recorded in the InnoDB
internal data dictionary.
A symptom of an out-of-sync data dictionary is that a
CREATE TABLE statement fails. If
this occurs, you should look in the server's error log. If the
log says that the table already exists inside the
InnoDB internal data dictionary, you have an
orphaned table inside the InnoDB tablespace
files that has no corresponding .frm file.
The error message looks like this:
InnoDB: Error: table test/parent already exists in InnoDB internal InnoDB: data dictionary. Have you deleted the .frm file InnoDB: and not used DROP TABLE? Have you used DROP DATABASE InnoDB: for InnoDB tables in MySQL version <= 3.23.43? InnoDB: See the Restrictions section of the InnoDB manual. InnoDB: You can drop the orphaned table inside InnoDB by InnoDB: creating an InnoDB table with the same name in another InnoDB: database and moving the .frm file to the current database. InnoDB: Then MySQL thinks the table exists, and DROP TABLE will InnoDB: succeed.
You can drop the orphaned table by following the instructions
given in the error message. If you are still unable to use
DROP TABLE successfully, the
problem may be due to name completion in the
mysql client. To work around this problem,
start the mysql client with the
--skip-auto-rehash
option and try DROP TABLE again.
(With name completion on, mysql tries to
construct a list of table names, which fails when a problem such
as just described exists.)
Another symptom of an out-of-sync data dictionary is that MySQL
prints an error that it cannot open a
.InnoDB file:
ERROR 1016: Can't open file: 'child2.InnoDB'. (errno: 1)
In the error log you can find a message like this:
InnoDB: Cannot find table test/child2 from the internal data dictionary InnoDB: of InnoDB though the .frm file for the table exists. Maybe you InnoDB: have deleted and recreated InnoDB data files but have forgotten InnoDB: to delete the corresponding .frm files of InnoDB tables?
This means that there is an orphaned .frm
file without a corresponding table inside
InnoDB. You can drop the orphaned
.frm file by deleting it manually.
If MySQL crashes in the middle of an ALTER
TABLE operation, you may end up with an orphaned
temporary table inside the InnoDB tablespace.
Using the Table Monitor, you can see listed a table with a name
that begins with #sql-. You can perform SQL
statements on tables whose name contains the character
“#” if you enclose the name
within backticks. Thus, you can drop such an orphaned table like
any other orphaned table using the method described earlier. To
copy or rename a file in the Unix shell, you need to put the
file name in double quotes if the file name contains
“#”.
With innodb_file_per_table enabled, the
following message might occur if the .frm or
.ibd files (or both) are missing:
InnoDB: in InnoDB data dictionary has tablespace id N,
InnoDB: but tablespace with that id or name does not exist. Have
InnoDB: you deleted or moved .ibd files?
InnoDB: This may also be a table created with CREATE TEMPORARY TABLE
InnoDB: whose .ibd and .frm files MySQL automatically removed, but the
InnoDB: table still exists in the InnoDB internal data dictionary.
If this occurs, try the following procedure to resolve the problem:
Create a matching
.frmfile in some other database directory and copy it to the database directory where the orphan table is located.Issue
DROP TABLEfor the original table. That should successfully drop the table andInnoDBshould print a warning to the error log that the.ibdfile was missing.
Warning
Do not convert MySQL system tables in the
mysql database from MyISAM
to InnoDB tables! This is an unsupported
operation. If you do this, MySQL does not restart until you
restore the old system tables from a backup or re-generate them
with the mysql_install_db script.
Warning
It is not a good idea to configure InnoDB to
use data files or log files on NFS volumes. Otherwise, the files
might be locked by other processes and become unavailable for
use by MySQL.
A table cannot contain more than 1000 columns.
The internal maximum key length is 3500 bytes, but MySQL itself restricts this to 3072 bytes. (1024 bytes for non-64-bit builds before MySQL 5.0.17, and for all builds before 5.0.15.)
Index key prefixes can be up to 767 bytes. See Section 12.1.8, “
CREATE INDEXSyntax”.The maximum row length, except for variable-length columns (
VARBINARY,VARCHAR,BLOBandTEXT), is slightly less than half of a database page. That is, the maximum row length is about 8000 bytes.LONGBLOBandLONGTEXTcolumns must be less than 4GB, and the total row length, includingBLOBandTEXTcolumns, must be less than 4GB.If a row is less than half a page long, all of it is stored locally within the page. If it exceeds half a page, variable-length columns are chosen for external off-page storage until the row fits within half a page, as described in Section 13.2.11.2, “File Space Management”.
Although
InnoDBsupports row sizes larger than 65535 internally, you cannot define a row containingVARBINARYorVARCHARcolumns with a combined size larger than 65535:mysql>
CREATE TABLE t (a VARCHAR(8000), b VARCHAR(10000),->c VARCHAR(10000), d VARCHAR(10000), e VARCHAR(10000),->f VARCHAR(10000), g VARCHAR(10000)) ENGINE=InnoDB;ERROR 1118 (42000): Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. You have to change some columns to TEXT or BLOBsOn some older operating systems, files must be less than 2GB. This is not a limitation of
InnoDBitself, but if you require a large tablespace, you will need to configure it using several smaller data files rather than one or a file large data files.The combined size of the
InnoDBlog files must be less than 4GB.The minimum tablespace size is 10MB. The maximum tablespace size is four billion database pages (64TB). This is also the maximum size for a table.
InnoDBtables do not supportFULLTEXTindexes.InnoDBtables do not support spatial data types before MySQL 5.0.16. As of 5.0.16,InnoDBsupports spatial data types, but not indexes on them.ANALYZE TABLEdetermines index cardinality (as displayed in theCardinalitycolumn ofSHOW INDEXoutput) by doing ten random dives to each of the index trees and updating index cardinality estimates accordingly. Because these are only estimates, repeated runs ofANALYZE TABLEmay produce different numbers. This makesANALYZE TABLEfast onInnoDBtables but not 100% accurate because it does not take all rows into account.MySQL uses index cardinality estimates only in join optimization. If some join is not optimized in the right way, you can try using
ANALYZE TABLE. In the few cases thatANALYZE TABLEdoes not produce values good enough for your particular tables, you can useFORCE INDEXwith your queries to force the use of a particular index, or set themax_seeks_for_keysystem variable to ensure that MySQL prefers index lookups over table scans. See Section 5.1.3, “Server System Variables”, and Section B.1.6, “Optimizer-Related Issues”.SHOW TABLE STATUSdoes not give accurate statistics onInnoDBtables, except for the physical size reserved by the table. The row count is only a rough estimate used in SQL optimization.InnoDBdoes not keep an internal count of rows in a table. (In practice, this would be somewhat complicated due to multi-versioning.) To process aSELECT COUNT(*) FROM tstatement,InnoDBmust scan an index of the table, which takes some time if the index is not entirely in the buffer pool. If your table does not change often, using the MySQL query cache is a good solution. To get a fast count, you have to use a counter table you create yourself and let your application update it according to the inserts and deletes it does.SHOW TABLE STATUSalso can be used if an approximate row count is sufficient. See Section 13.2.13.1, “InnoDBPerformance Tuning Tips”.On Windows,
InnoDBalways stores database and table names internally in lowercase. To move databases in a binary format from Unix to Windows or from Windows to Unix, you should create all databases and tables using lowercase names.For an
AUTO_INCREMENTcolumn, you must always define an index for the table, and that index must contain just theAUTO_INCREMENTcolumn. InMyISAMtables, theAUTO_INCREMENTcolumn may be part of a multi-column index.In MySQL 5.0 before MySQL 5.0.3,
InnoDBdoes not support theAUTO_INCREMENTtable option for setting the initial sequence value in aCREATE TABLEorALTER TABLEstatement. To set the value withInnoDB, insert a dummy row with a value one less and delete that dummy row, or insert the first row with an explicit value specified.While initializing a previously specified
AUTO_INCREMENTcolumn on a table,InnoDBsets an exclusive lock on the end of the index associated with theAUTO_INCREMENTcolumn. In accessing the auto-increment counter,InnoDBuses a specific table lock modeAUTO-INCwhere the lock lasts only to the end of the current SQL statement, not to the end of the entire transaction. Other clients cannot insert into the table while theAUTO-INCtable lock is held; see Section 13.2.4.3, “AUTO_INCREMENTHandling inInnoDB”.When you restart the MySQL server,
InnoDBmay reuse an old value that was generated for anAUTO_INCREMENTcolumn but never stored (that is, a value that was generated during an old transaction that was rolled back).When an
AUTO_INCREMENTcolumn runs out of values,InnoDBwraps aBIGINTto-9223372036854775808andBIGINT UNSIGNEDto1. However,BIGINTvalues have 64 bits, so if you were to insert one million rows per second, it would still take nearly three hundred thousand years beforeBIGINTreached its upper bound. With all other integer type columns, a duplicate-key error results. This is similar to howMyISAMworks, because it is mostly general MySQL behavior and not about any storage engine in particular.DELETE FROMdoes not regenerate the table but instead deletes all rows, one by one.tbl_nameUnder some conditions,
TRUNCATEfor antbl_nameInnoDBtable is mapped toDELETE FROMand does not reset thetbl_nameAUTO_INCREMENTcounter. See Section 12.2.10, “TRUNCATESyntax”.In MySQL 5.0, the MySQL
LOCK TABLESoperation acquires two locks on each table ifinnodb_table_locks = 1(the default). In addition to a table lock on the MySQL layer, it also acquires anInnoDBtable lock. Older versions of MySQL did not acquireInnoDBtable locks; the old behavior can be selected by settinginnodb_table_locks = 0. If noInnoDBtable lock is acquired,LOCK TABLEScompletes even if some records of the tables are being locked by other transactions.All
InnoDBlocks held by a transaction are released when the transaction is committed or aborted. Thus, it does not make much sense to invokeLOCK TABLESonInnoDBtables inautocommit = 1mode, because the acquiredInnoDBtable locks would be released immediately.Sometimes it would be useful to lock further tables in the course of a transaction. Unfortunately,
LOCK TABLESin MySQL performs an implicitCOMMITandUNLOCK TABLES. AnInnoDBvariant ofLOCK TABLEShas been planned that can be executed in the middle of a transaction.The
LOAD TABLE FROM MASTERstatement for setting up replication slave servers does not work forInnoDBtables. A workaround is to alter the table toMyISAMon the master, then do the load, and after that alter the master table back toInnoDB. Do not do this if the tables useInnoDB-specific features such as foreign keys.The default database page size in
InnoDBis 16KB. By recompiling the code, you can set it to values ranging from 8KB to 64KB. You must update the values ofUNIV_PAGE_SIZEandUNIV_PAGE_SIZE_SHIFTin theuniv.isource file.Currently, cascaded foreign key actions to not activate triggers.
You cannot create a table with a column name that matches the name of an internal InnoDB column (including
DB_ROW_ID,DB_TRX_ID,DB_ROLL_PTR, andDB_MIX_ID). In versions of MySQL before 5.0.21 this would cause a crash, since 5.0.21 the server will report error 1005 and refers to error –1 in the error message. This limitation applies only to use of the names in uppercase.As of MySQL 5.0.19,
InnoDBdoes not ignore trailing spaces when comparingBINARYorVARBINARYcolumn values. See Section 10.4.2, “TheBINARYandVARBINARYTypes” and Section C.1.64, “Changes in MySQL 5.0.19 (04 March 2006)”.InnoDBhas a limit of 1023 concurrent transactions that have created undo records by modifying data. Workarounds include keeping transactions as small and fast as possible, delaying changes until near the end of the transaction, and using stored routines to reduce client-server latency delays. Applications should commit transactions before doing time-consuming client-side operations.
The MERGE storage engine, also known as the
MRG_MyISAM engine, is a collection of identical
MyISAM tables that can be used as one.
“Identical” means that all tables have identical column
and index information. You cannot merge MyISAM
tables in which the columns are listed in a different order, do not
have exactly the same columns, or have the indexes in different
order. However, any or all of the MyISAM tables
can be compressed with myisampack. See
Section 4.6.5, “myisampack — Generate Compressed, Read-Only MyISAM Tables”. Differences in table options such as
AVG_ROW_LENGTH, MAX_ROWS, or
PACK_KEYS do not matter.
When you create a MERGE table, MySQL creates two
files on disk. The files have names that begin with the table name
and have an extension to indicate the file type. An
.frm file stores the table format, and an
.MRG file contains the names of the tables that
should be used as one. The tables do not have to be in the same
database as the MERGE table itself.
Starting with MySQL 5.0.36 the underlying table definitions and
indexes must conform more closely to the definition of the
MERGE table. Conformance will be checked when the
merged tables are opened, not when the MERGE
table is created. This means that changes to the definitions of
tables within a MERGE may cause a failure when
the MERGE table is accessed.
You can use SELECT,
DELETE,
UPDATE, and
INSERT on MERGE
tables. You must have SELECT,
UPDATE, and
DELETE privileges on the
MyISAM tables that you map to a
MERGE table.
Note
The use of MERGE tables entails the following
security issue: If a user has access to MyISAM
table t, that user can create a
MERGE table m that
accesses t. However, if the user's
privileges on t are subsequently
revoked, the user can continue to access
t by doing so through
m. If this behavior is undesirable, you
can start the server with the new
--skip-merge option to disable the
MERGE storage engine. This option is available
as of MySQL 5.0.24.
If you DROP the MERGE table,
you are dropping only the MERGE specification.
The underlying tables are not affected.
To create a MERGE table, you must specify a
UNION=(
clause that indicates which list-of-tables)MyISAM tables you
want to use as one. You can optionally specify an
INSERT_METHOD option if you want inserts for the
MERGE table to take place in the first or last
table of the UNION list. Use a value
of FIRST or LAST to cause
inserts to be made in the first or last table, respectively. If you
do not specify an INSERT_METHOD option or if you
specify it with a value of NO, attempts to insert
rows into the MERGE table result in an error.
The following example shows how to create a MERGE
table:
mysql>CREATE TABLE t1 (->a INT NOT NULL AUTO_INCREMENT PRIMARY KEY,->message CHAR(20)) ENGINE=MyISAM;mysql>CREATE TABLE t2 (->a INT NOT NULL AUTO_INCREMENT PRIMARY KEY,->message CHAR(20)) ENGINE=MyISAM;mysql>INSERT INTO t1 (message) VALUES ('Testing'),('table'),('t1');mysql>INSERT INTO t2 (message) VALUES ('Testing'),('table'),('t2');mysql>CREATE TABLE total (->a INT NOT NULL AUTO_INCREMENT,->message CHAR(20), INDEX(a))->ENGINE=MERGE UNION=(t1,t2) INSERT_METHOD=LAST;
The older term TYPE is supported as a synonym for
ENGINE for backward compatibility, but
ENGINE is the preferred term and
TYPE is deprecated.
Note that the a column is indexed as a
PRIMARY KEY in the underlying
MyISAM tables, but not in the
MERGE table. There it is indexed but not as a
PRIMARY KEY because a MERGE
table cannot enforce uniqueness over the set of underlying tables.
In MySQL 5.0.36 and higher, when a table that is part of a
MERGE table is opened, the following checks are
applied before opening each table. If any table fails the
conformance checks, then the operation that triggered the opening of
the table will fail. The conformance checks applied to each table
are:
Table must have exactly the same amount of columns that
MERGEtable has.Column order in the
MERGEtable must match the column order in the underlying tables.Additionally, the specification for each column in the parent
MERGEtable and the underlying table are compared. For each column, MySQL checks:Column type in the underlying table equals the column type of
MERGEtable.Column length in the underlying table equals the column length of
MERGEtable.Column of underlying table and column of
MERGEtable can beNULL.
Underlying table must have at least the same amount of keys that merge table has. The underlying table may have more keys than the
MERGEtable, but cannot have less.Note
A known issue exists that keys on the some columns must be identical in order in both the
MERGEtable and the underlyingMyISAMtable. See Bug#33653.For each key:
Check whether the key type of underlying table equals the key type of merge table.
Check whether the number of key parts (that is, multiple columns within a compound key) in the underlying table key definition equals the number of key parts in merge table key definition.
For each key part:
Check whether key part lengths are equal.
Check whether key part types are equal.
Check whether key part languages are equal.
Check whether key part can be
NULL.
After creating the MERGE table, you can issue
queries that operate on the group of tables as a whole:
mysql> SELECT * FROM total;
+---+---------+
| a | message |
+---+---------+
| 1 | Testing |
| 2 | table |
| 3 | t1 |
| 1 | Testing |
| 2 | table |
| 3 | t2 |
+---+---------+
To remap a MERGE table to a different collection
of MyISAM tables, you can use one of the
following methods:
MERGE tables can help you solve the following
problems:
Easily manage a set of log tables. For example, you can put data from different months into separate tables, compress some of them with myisampack, and then create a
MERGEtable to use them as one.Obtain more speed. You can split a big read-only table based on some criteria, and then put individual tables on different disks. A
MERGEtable on this could be much faster than using the big table.Perform more efficient searches. If you know exactly what you are looking for, you can search in just one of the split tables for some queries and use a
MERGEtable for others. You can even have many differentMERGEtables that use overlapping sets of tables.Perform more efficient repairs. It is easier to repair individual tables that are mapped to a
MERGEtable than to repair a single large table.Instantly map many tables as one. A
MERGEtable need not maintain an index of its own because it uses the indexes of the individual tables. As a result,MERGEtable collections are very fast to create or remap. (Note that you must still specify the index definitions when you create aMERGEtable, even though no indexes are created.)If you have a set of tables from which you create a large table on demand, you should instead create a
MERGEtable on them on demand. This is much faster and saves a lot of disk space.Exceed the file size limit for the operating system. Each
MyISAMtable is bound by this limit, but a collection ofMyISAMtables is not.You can create an alias or synonym for a
MyISAMtable by defining aMERGEtable that maps to that single table. There should be no really notable performance impact from doing this (only a couple of indirect calls andmemcpy()calls for each read).
The disadvantages of MERGE tables are:
You can use only identical
MyISAMtables for aMERGEtable.You cannot use a number of
MyISAMfeatures inMERGEtables. For example, you cannot createFULLTEXTindexes onMERGEtables. (You can, of course, createFULLTEXTindexes on the underlyingMyISAMtables, but you cannot search theMERGEtable with a full-text search.)If the
MERGEtable is nontemporary, all underlyingMyISAMtables must be nontemporary, too. If theMERGEtable is temporary, theMyISAMtables can be any mix of temporary and nontemporary.MERGEtables use more file descriptors. If 10 clients are using aMERGEtable that maps to 10 tables, the server uses (10 × 10) + 10 file descriptors. (10 data file descriptors for each of the 10 clients, and 10 index file descriptors shared among the clients.)Key reads are slower. When you read a key, the
MERGEstorage engine needs to issue a read on all underlying tables to check which one most closely matches the given key. To read the next key, theMERGEstorage engine needs to search the read buffers to find the next key. Only when one key buffer is used up does the storage engine need to read the next key block. This makesMERGEkeys much slower oneq_refsearches, but not much slower onrefsearches. See Section 12.3.2, “EXPLAINSyntax”, for more information abouteq_refandref.
Additional resources
A forum dedicated to the
MERGEstorage engine is available at http://forums.mysql.com/list.php?93.
The following are known problems with MERGE
tables:
If you use
ALTER TABLEto change aMERGEtable to another storage engine, the mapping to the underlying tables is lost. Instead, the rows from the underlyingMyISAMtables are copied into the altered table, which then uses the specified storage engine.REPLACEdoes not work as expected because theMERGEengine cannot enforce uniqueness over the set of underlying tables. The two key facts are:REPLACEcan detect unique key violations only in the underlying table to which it is going to write (which is determined byINSERT_METHOD). This differs from violations in theMERGEtable itself.If
REPLACEdetects such a violation, it will only change the corresponding row in the first underlying table in which the row is present, whereas a row with the same unique key value may be present in all underlying tables.
Similar considerations apply for
INSERT ... ON DUPLICATE KEY UPDATE.You should not use
REPAIR TABLE,OPTIMIZE TABLE,DROP TABLE,ALTER TABLE,DELETEwithout aWHEREclause,TRUNCATE TABLE, orANALYZE TABLEon any of the tables that are mapped into an openMERGEtable. If you do so, theMERGEtable may still refer to the original table, which yields unexpected results. The easiest way to work around this deficiency is to ensure that noMERGEtables remain open by issuing aFLUSH TABLESstatement prior to performing any of those operations.The unexpected results include the possibility that the operation on the
MERGEtable will report table corruption. However, if this occurs after operations on the underlyingMyISAMtables such as those listed in the previous paragraph (REPAIR TABLE,OPTIMIZE TABLE, and so forth), the corruption message is spurious. To deal with this, issue aFLUSH TABLESstatement after modifying theMyISAMtables.DROP TABLEon a table that is in use by aMERGEtable does not work on Windows because theMERGEstorage engine's table mapping is hidden from the upper layer of MySQL. Windows does not allow open files to be deleted, so you first must flush allMERGEtables (withFLUSH TABLES) or drop theMERGEtable before dropping the table.A
MERGEtable cannot maintain uniqueness constraints over the entire table. When you perform anINSERT, the data goes into the first or lastMyISAMtable (depending on the value of theINSERT_METHODoption). MySQL ensures that unique key values remain unique within thatMyISAMtable, but not across all the tables in the collection.The
INSERT_METHODtable option for aMERGEtable indicates which underlyingMyISAMtable to use for inserts into theMERGEtable. However, use of theAUTO_INCREMENTtable option for thatMyISAMtable has no effect for inserts into theMERGEtable until at least one row has been inserted directly into theMyISAMtable.In MySQL 5.0.36 and later, the definition of the
MyISAMtables and theMERGEtable are checked when the tables are accessed (for example, as part of aSELECTorINSERTstatement). The checks ensure that the definitions of the tables and the parentMERGEtable definition match by comparing column order, types, sizes and associated indexes. If there is a difference between the tables then an error will be returned and the statement will fail.Because these checks take place when the tables are opened, any changes to the definition of a single table, including column changes, column ordering and engine alterations will cause the statement to fail.
In MySQL 5.0.35 and earlier:
When you create or alter
MERGEtable, there is no check to ensure that the underlying tables are existingMyISAMtables and have identical structures. When theMERGEtable is used, MySQL checks that the row length for all mapped tables is equal, but this is not foolproof. If you create aMERGEtable from dissimilarMyISAMtables, you are very likely to run into strange problems.Similarly, if you create a
MERGEtable from non-MyISAMtables, or if you drop an underlying table or alter it to be a non-MyISAMtable, no error for theMERGEtable occurs until later when you attempt to use it.Because the underlying
MyISAMtables need not exist when theMERGEtable is created, you can create the tables in any order, as long as you do not use theMERGEtable until all of its underlying tables are in place. Also, if you can ensure that aMERGEtable will not be used during a given period, you can perform maintenance operations on the underlying tables, such as backing up or restoring them, altering them, or dropping and recreating them. It is not necessary to redefine theMERGEtable temporarily to exclude the underlying tables while you are operating on them.
The order of indexes in the
MERGEtable and its underlying tables should be the same. If you useALTER TABLEto add aUNIQUEindex to a table used in aMERGEtable, and then useALTER TABLEto add a nonunique index on theMERGEtable, the index ordering is different for the tables if there was already a nonunique index in the underlying table. (This happens becauseALTER TABLEputsUNIQUEindexes before nonunique indexes to facilitate rapid detection of duplicate keys.) Consequently, queries on tables with such indexes may return unexpected results.If you encounter an error message similar to ERROR 1017 (HY000): Can't find file: '
mm.MRG' (errno: 2) it generally indicates that some of the base tables are not using theMyISAMstorage engine. Confirm that all of these tables areMyISAM.The maximum number of rows in a
MERGEtable is 232 (~4.295E+09; the same as for aMyISAMtable). It is not possible to merge multipleMyISAMtables into a singleMERGEtable that would have more than this number of rows. However, if you build MySQL using the--with-big-tablesoption, then the maximum number of rows is increased to 264 (1.844E+19); for more information, see Section 2.16.2, “Typical configure Options”.Note
Beginning with MySQL 5.0.4, all standard binaries are built with this option.
The
MERGEstorage engine does not supportINSERT DELAYEDstatements.Using
MERGEon underlyingMyISAMtables that have different row formats is possible.
As of MySQL 5.0.44, if a MERGE table cannot be
opened or used because of a problem with an underlying table,
CHECK TABLE displays information
about which table caused the problem.
The MEMORY storage engine creates tables with
contents that are stored in memory. Formerly, these were known as
HEAP tables. MEMORY is the
preferred term, although HEAP remains supported
for backward compatibility.
Each MEMORY table is associated with one disk
file. The file name begins with the table name and has an extension
of .frm to indicate that it stores the table
definition.
To specify explicitly that you want to create a
MEMORY table, indicate that with an
ENGINE table option:
CREATE TABLE t (i INT) ENGINE = MEMORY;
The older term TYPE is supported as a synonym for
ENGINE for backward compatibility, but
ENGINE is the preferred term and
TYPE is deprecated.
As indicated by the name, MEMORY tables are
stored in memory. They use hash indexes by default, which makes them
very fast, and very useful for creating temporary tables. However,
when the server shuts down, all rows stored in
MEMORY tables are lost. The tables themselves
continue to exist because their definitions are stored in
.frm files on disk, but they are empty when the
server restarts.
This example shows how you might create, use, and remove a
MEMORY table:
mysql>CREATE TABLE test ENGINE=MEMORY->SELECT ip,SUM(downloads) AS down->FROM log_table GROUP BY ip;mysql>SELECT COUNT(ip),AVG(down) FROM test;mysql>DROP TABLE test;
MEMORY tables have the following characteristics:
Space for
MEMORYtables is allocated in small blocks. Tables use 100% dynamic hashing for inserts. No overflow area or extra key space is needed. No extra space is needed for free lists. Deleted rows are put in a linked list and are reused when you insert new data into the table.MEMORYtables also have none of the problems commonly associated with deletes plus inserts in hashed tables.MEMORYtables can have up to 32 indexes per table, 16 columns per index and a maximum key length of 500 bytes.The
MEMORYstorage engine implements bothHASHandBTREEindexes. You can specify one or the other for a given index by adding aUSINGclause as shown here:CREATE TABLE lookup (id INT, INDEX USING HASH (id)) ENGINE = MEMORY; CREATE TABLE lookup (id INT, INDEX USING BTREE (id)) ENGINE = MEMORY;General characteristics of B-tree and hash indexes are described in Section 7.4.4, “How MySQL Uses Indexes”.
You can have nonunique keys in a
MEMORYtable. (This is an uncommon feature for implementations of hash indexes.)If you have a hash index on a
MEMORYtable that has a high degree of key duplication (many index entries containing the same value), updates to the table that affect key values and all deletes are significantly slower. The degree of this slowdown is proportional to the degree of duplication (or, inversely proportional to the index cardinality). You can use aBTREEindex to avoid this problem.Columns that are indexed can contain
NULLvalues.MEMORYtables use a fixed-length row storage format.MEMORYincludes support forAUTO_INCREMENTcolumns.You can use
INSERT DELAYEDwithMEMORYtables. See Section 12.2.5.2, “INSERT DELAYEDSyntax”.MEMORYtables are shared among all clients (just like any other non-TEMPORARYtable).MEMORYtable contents are stored in memory, which is a property thatMEMORYtables share with internal tables that the server creates on the fly while processing queries. However, the two types of tables differ in thatMEMORYtables are not subject to storage conversion, whereas internal tables are:If an internal table becomes too large, the server automatically converts it to an on-disk table. The size limit is determined by the value of the
tmp_table_sizesystem variable.MEMORYtables are never converted to disk tables.The maximum size of
MEMORYtables is limited by themax_heap_table_sizesystem variable, which has a default value of 16MB. To have larger (or smaller)MEMORYtables, you must change the value of this variable. The value in effect at the time aMEMORYtable is created is the value used for the life of the table. (If you useALTER TABLEorTRUNCATE TABLE, the value in effect at that time becomes the new maximum size for the table. A server restart also sets the maximum size of existingMEMORYtables to the globalmax_heap_table_sizevalue.) You can set the size for individual tables as described later in this section.
The server needs sufficient memory to maintain all
MEMORYtables that are in use at the same time.Memory used by a
MEMORYtable is not reclaimed if you delete individual rows from the table. Memory is only reclaimed when the entire table is deleted. Memory that was previously used for rows that have been deleted will be re-used for new rows only within the same table. To free up the memory used by rows that have been deleted you should useALTER TABLE ENGINE=MEMORYto force a table rebuild.To free all the memory used by a
MEMORYtable when you no longer require its contents, you should executeDELETEorTRUNCATE TABLE, or remove the table altogether usingDROP TABLE.If you want to populate a
MEMORYtable when the MySQL server starts, you can use the--init-fileoption. For example, you can put statements such asINSERT INTO ... SELECTorLOAD DATA INFILEinto this file to load the table from a persistent data source. See Section 5.1.2, “Server Command Options”, and Section 12.2.6, “LOAD DATA INFILESyntax”.If you are using replication, the master server's
MEMORYtables become empty when it is shut down and restarted. However, a slave is not aware that these tables have become empty, so it returns out-of-date content if you select data from them. When aMEMORYtable is used on the master for the first time since the master was started, aDELETEstatement is written to the master's binary log automatically, thus synchronizing the slave to the master again. Note that even with this strategy, the slave still has outdated data in the table during the interval between the master's restart and its first use of the table. However, if you use the--init-fileoption to populate theMEMORYtable on the master at startup, it ensures that this time interval is zero.The memory needed for one row in a
MEMORYtable is calculated using the following expression:SUM_OVER_ALL_BTREE_KEYS(
max_length_of_key+ sizeof(char*) × 4) + SUM_OVER_ALL_HASH_KEYS(sizeof(char*) × 2) + ALIGN(length_of_row+1, sizeof(char*))ALIGN()represents a round-up factor to cause the row length to be an exact multiple of thecharpointer size.sizeof(char*)is 4 on 32-bit machines and 8 on 64-bit machines.
As mentioned earlier, the
max_heap_table_size system variable
sets the limit on the maximum size of MEMORY
tables. To control the maximum size for individual tables, set the
session value of this variable before creating each table. (Do not
change the global
max_heap_table_size value unless
you intend the value to be used for MEMORY tables
created by all clients.) The following example creates two
MEMORY tables, with a maximum size of 1MB and
2MB, respectively:
mysql>SET max_heap_table_size = 1024*1024;Query OK, 0 rows affected (0.00 sec) mysql>CREATE TABLE t1 (id INT, UNIQUE(id)) ENGINE = MEMORY;Query OK, 0 rows affected (0.01 sec) mysql>SET max_heap_table_size = 1024*1024*2;Query OK, 0 rows affected (0.00 sec) mysql>CREATE TABLE t2 (id INT, UNIQUE(id)) ENGINE = MEMORY;Query OK, 0 rows affected (0.00 sec)
Both tables will revert to the server's global
max_heap_table_size value if the
server restarts.
You can also specify a MAX_ROWS table option in
CREATE TABLE statements for
MEMORY tables to provide a hint about the number
of rows you plan to store in them. This does not allow the table to
grow beyond the max_heap_table_size
value, which still acts as a constraint on maximum table size. For
maximum flexibility in being able to use
MAX_ROWS, set
max_heap_table_size at least as
high as the value to which you want each MEMORY
table to be able to grow.
Additional resources
A forum dedicated to the
MEMORYstorage engine is available at http://forums.mysql.com/list.php?92.
Sleepycat Software has provided MySQL with the Berkeley DB
transactional storage engine. This storage engine typically is
called BDB for short. BDB
tables may have a greater chance of surviving crashes and are also
capable of COMMIT and
ROLLBACK
operations on transactions.
Support for the BDB storage engine is included in
MySQL source distributions, which come with a BDB
distribution that is patched to make it work with MySQL. You cannot
use an unpatched version of BDB with MySQL.
BDB support will be removed
Note that, as of MySQL 5.1, BDB isn't supported
any longer.
For general information about Berkeley DB, please visit the Sleepycat Web site, http://www.sleepycat.com/.
Currently, we know that the BDB storage engine
works with the following operating systems:
Linux 2.x Intel
Sun Solaris (SPARC and x86)
FreeBSD 4.x/5.x (x86, sparc64)
IBM AIX 4.3.x
SCO OpenServer
SCO UnixWare 7.1.x
Windows
The BDB storage engine does
not work with the following operating
systems:
Linux 2.x Alpha
Linux 2.x AMD64
Linux 2.x IA-64
Linux 2.x s390
Mac OS X
Note
The preceding lists are not complete. We update them as we receive more information.
If you build MySQL from source with support for
BDB tables, but the following error occurs when
you start mysqld, it means that the
BDB storage engine is not supported for your
architecture:
bdb: architecture lacks fast mutexes: applications cannot be threaded Can't init databases
In this case, you must rebuild MySQL without
BDB support or start the server with the
--skip-bdb option.
If you have downloaded a binary version of MySQL that includes support for Berkeley DB, simply follow the usual binary distribution installation instructions.
If you build MySQL from source, you can enable
BDB support by invoking
configure with the
--with-berkeley-db option in addition to any
other options that you normally use. Download a MySQL
5.0 distribution, change location into its top-level
directory, and run this command:
shell> ./configure --with-berkeley-db [other-options]
For more information, Section 2.15, “Installing MySQL from tar.gz Packages on Other
Unix-Like Systems”, and
Section 2.16, “MySQL Installation Using a Source Distribution”.
The following options to mysqld can be used to
change the behavior of the BDB storage engine.
For more information, see Section 5.1.2, “Server Command Options”.
Table 13.3. mysqld BDB Option/Variable Reference
| Name | Cmd-Line | Option file | System Var | Status Var | Var Scope | Dynamic |
|---|---|---|---|---|---|---|
| bdb_cache_size | Yes | Yes | Yes | Global | No | |
| bdb-home | Yes | Yes | Global | No | ||
| - Variable: bdb_home | Yes | Global | No | |||
| bdb-lock-detect | Yes | Yes | Global | No | ||
| - Variable: bdb_lock_detect | Yes | Global | No | |||
| bdb_log_buffer_size | Yes | Yes | Yes | Global | No | |
| bdb-logdir | Yes | Yes | Global | No | ||
| - Variable: bdb_logdir | Yes | Global | No | |||
| bdb_max_lock | Yes | Yes | Yes | Global | No | |
| bdb-no-recover | Yes | Yes | ||||
| bdb-shared-data | Yes | Yes | Global | No | ||
| - Variable: bdb_shared_data | Yes | Global | No | |||
| bdb-tmpdir | Yes | Yes | Global | No | ||
| - Variable: bdb_tmpdir | Yes | Global | No | |||
| have_bdb | Yes | Global | No | |||
| skip-bdb | Yes | Yes | ||||
| skip-sync-bdb-logs | Yes | Yes | Yes | Global | No | |
| sync-bdb-logs | Yes | Yes | Global | No | ||
| - Variable: sync_bdb_logs | Yes | Global | No |
The base directory for
BDBtables. This should be the same directory that you use for--datadir.The
BDBlock detection method. The option value should beDEFAULT,OLDEST,RANDOM, orYOUNGEST.The
BDBlog file directory.Do not start Berkeley DB in recover mode.
Don't synchronously flush the
BDBlogs. This option is deprecated; use--skip-sync-bdb-logsinstead (see the description for--sync-bdb-logs).Start Berkeley DB in multi-process mode. (Do not use
DB_PRIVATEwhen initializing Berkeley DB.)The
BDBtemporary file directory.Disable the
BDBstorage engine.Synchronously flush the
BDBlogs. This option is enabled by default. Use--skip-sync-bdb-logsto disable it.
If you use the --skip-bdb option,
MySQL does not initialize the Berkeley DB library and this saves a
lot of memory. However, if you use this option, you cannot use
BDB tables. If you try to create a
BDB table, MySQL uses the default storage
engine instead.
Normally, you should start mysqld without the
--bdb-no-recover option if you
intend to use BDB tables. However, this may
cause problems when you try to start mysqld if
the BDB log files are corrupted. See
Section 2.17.2.3, “Starting and Troubleshooting the MySQL Server”.
With the bdb_max_lock variable,
you can specify the maximum number of locks that can be active on
a BDB table. The default is 10,000. You should
increase this if errors such as the following occur when you
perform long transactions or when mysqld has to
examine many rows to execute a query:
bdb: Lock table is out of available locks Got error 12 from ...
You may also want to change the
binlog_cache_size and
max_binlog_cache_size variables
if you are using large multiple-statement transactions. See
Section 5.2.3, “The Binary Log”.
See also Section 5.1.3, “Server System Variables”.
Each BDB table is stored on disk in two files.
The files have names that begin with the table name and have an
extension to indicate the file type. An .frm
file stores the table format, and a .db file
contains the table data and indexes.
To specify explicitly that you want a BDB
table, indicate that with an ENGINE table
option:
CREATE TABLE t (i INT) ENGINE = BDB;
The older term TYPE is supported as a synonym
for ENGINE for backward compatibility, but
ENGINE is the preferred term and
TYPE is deprecated.
BerkeleyDB is a synonym for
BDB in the ENGINE table
option.
The BDB storage engine provides transactional
tables. The way you use these tables depends on the autocommit
mode:
If you are running with autocommit enabled (which is the default), changes to
BDBtables are committed immediately and cannot be rolled back.If you are running with autocommit disabled, changes do not become permanent until you execute a
COMMITstatement. Instead of committing, you can executeROLLBACKto forget the changes.You can start a transaction with the
START TRANSACTIONorBEGINstatement to suspend autocommit, or withSET autocommit = 0to disable autocommit explicitly.
For more information about transactions, see
Section 12.4.1, “START TRANSACTION,
COMMIT, and
ROLLBACK Syntax”.
The BDB storage engine has the following
characteristics:
BDBtables can have up to 31 indexes per table, 16 columns per index, and a maximum key size of 1024 bytes.MySQL requires a primary key in each
BDBtable so that each row can be uniquely identified. If you don't create one explicitly by declaring aPRIMARY KEY, MySQL creates and maintains a hidden primary key for you. The hidden key has a length of five bytes and is incremented for each insert attempt. This key does not appear in the output ofSHOW CREATE TABLEorDESCRIBE.The primary key is faster than any other index, because it is stored together with the row data. The other indexes are stored as the key data plus the primary key, so it is important to keep the primary key as short as possible to save disk space and get better speed.
This behavior is similar to that of
InnoDB, where shorter primary keys save space not only in the primary index but in secondary indexes as well.If all columns that you access in a
BDBtable are part of the same index or part of the primary key, MySQL can execute the query without having to access the actual row. In aMyISAMtable, this can be done only if the columns are part of the same index.Sequential scanning is slower for
BDBtables than forMyISAMtables because the data inBDBtables is stored in B-trees and not in a separate data file.Key values are not prefix- or suffix-compressed like key values in
MyISAMtables. In other words, key information takes a little more space inBDBtables compared toMyISAMtables.There are often holes in the
BDBtable to allow you to insert new rows in the middle of the index tree. This makesBDBtables somewhat larger thanMyISAMtables.SELECT COUNT(*) FROMis slow fortbl_nameBDBtables, because no row count is maintained in the table.The optimizer needs to know the approximate number of rows in the table. MySQL solves this by counting inserts and maintaining this in a separate segment in each
BDBtable. If you don't issue a lot ofDELETEorROLLBACKstatements, this number should be accurate enough for the MySQL optimizer. However, MySQL stores the number only on close, so it may be incorrect if the server terminates unexpectedly. It should not be fatal even if this number is not 100% correct. You can update the row count by usingANALYZE TABLEorOPTIMIZE TABLE. See Section 12.5.2.1, “ANALYZE TABLESyntax”, and Section 12.5.2.5, “OPTIMIZE TABLESyntax”.Internal locking in
BDBtables is done at the page level.LOCK TABLESworks onBDBtables as with other tables. If you do not useLOCK TABLES, MySQL issues an internal multiple-write lock on the table (a lock that does not block other writers) to ensure that the table is properly locked if another thread issues a table lock.To support transaction rollback, the
BDBstorage engine maintains log files. For maximum performance, you can use the--bdb-logdiroption to place theBDBlogs on a different disk than the one where your databases are located.MySQL performs a checkpoint each time a new
BDBlog file is started, and removes anyBDBlog files that are not needed for current transactions. You can also useFLUSH LOGSat any time to checkpoint the Berkeley DB tables.For disaster recovery, you should use table backups plus MySQL's binary log. See Section 6.1, “Database Backups”.
Warning
If you delete old log files that are still in use,
BDBis not able to do recovery at all and you may lose data if something goes wrong.Applications must always be prepared to handle cases where any change of a
BDBtable may cause an automatic rollback and any read may fail with a deadlock error.If you get a full disk with a
BDBtable, you get an error (probably error 28) and the transaction should roll back. This contrasts withMyISAMtables, for which mysqld waits for sufficient free disk space before continuing.
The following list indicates restrictions that you must observe
when using BDB tables:
Each
BDBtable stores in its.dbfile the path to the file as it was created. This is done to enable detection of locks in a multi-user environment that supports symlinks. As a consequence of this, it is not possible to moveBDBtable files from one database directory to another.When making backups of
BDBtables, you must either use mysqldump or else make a backup that includes the files for eachBDBtable (the.frmand.dbfiles) as well as theBDBlog files. TheBDBstorage engine stores unfinished transactions in its log files and requires them to be present when mysqld starts. TheBDBlogs are the files in the data directory with names of the formlog.(ten digits).NNNNNNNNNNIf a column that allows
NULLvalues has a unique index, only a singleNULLvalue is allowed. This differs from other storage engines, which allow multipleNULLvalues in unique indexes.
If the following error occurs when you start mysqld after upgrading, it means that the current version of
BDBdoesn't support the old log file format:bdb: Ignoring log file: .../log.
NNNNNNNNNN: unsupported log version #In this case, you must delete all
BDBlogs from your data directory (the files that have names of the formlog.) and restart mysqld. We also recommend that you then use mysqldump --opt to dump yourNNNNNNNNNNBDBtables, drop the tables, and restore them from the dump file.If autocommit mode is disabled and you drop a
BDBtable that is referenced in another transaction, you may get error messages of the following form in your MySQL error log:001119 23:43:56 bdb: Missing log fileid entry 001119 23:43:56 bdb: txn_abort: Log undo failed for LSN: 1 3644744: InvalidThis is not fatal, but the fix is not trivial. Avoid dropping
BDBtables except while autocommit mode is enabled.
The EXAMPLE storage engine is a stub engine that
does nothing. Its purpose is to serve as an example in the MySQL
source code that illustrates how to begin writing new storage
engines. As such, it is primarily of interest to developers.
The EXAMPLE storage engine is included in MySQL
binary distributions. To enable this storage engine if you build
MySQL from source, invoke configure with the
--with-example-storage-engine option.
To examine the source for the EXAMPLE engine,
look in the sql/examples directory of a MySQL
source distribution.
When you create an EXAMPLE table, the server
creates a table format file in the database directory. The file
begins with the table name and has an .frm
extension. No other files are created. No data can be stored into
the table. Retrievals return an empty result.
mysql>CREATE TABLE test (i INT) ENGINE = EXAMPLE;Query OK, 0 rows affected (0.78 sec) mysql>INSERT INTO test VALUES(1),(2),(3);ERROR 1031 (HY000): Table storage engine for 'test' doesn't have this option mysql>SELECT * FROM test;Empty set (0.31 sec)
The EXAMPLE storage engine does not support
indexing.
The FEDERATED storage engine is available
beginning with MySQL 5.0.3. It is a storage engine that accesses
data in tables of remote databases rather than in local tables.
The FEDERATED storage engine is available
beginning with MySQL 5.0.3. This storage engine enables data to be
accessed from a remote MySQL database on a local server without
using replication or cluster technology. When using a
FEDERATED table, queries on the local server are
automatically executed on the remote (federated) tables. No data is
stored on the local tables.
To include the FEDERATED storage engine if you
build MySQL from source, invoke configure with
the --with-federated-storage-engine option.
Beginning with MySQL 5.0.64, the FEDERATED
storage engine is not enabled by default in the running server; to
enable FEDERATED, you must start the MySQL server
binary using the --federated option.
To examine the source for the FEDERATED engine,
look in the sql directory of a source
distribution for MySQL 5.0.3 or newer.
Additional resources
A forum dedicated to the
FEDERATEDstorage engine is available at http://forums.mysql.com/list.php?105.
MySQL Enterprise
MySQL Enterprise subscribers will find MySQL Knowledge Base
articles about the FEDERATED storage engine at
FEDERATED Storage Engine. Access to the Knowledge Base
collection of articles is one of the advantages of subscribing to
MySQL Enterprise. For more information, see
http://www.mysql.com/products/enterprise/advisors.html.
When you create a FEDERATED table, the server
creates a table format file in the database directory. The file
begins with the table name and has an .frm
extension. No other files are created, because the actual data is
in a remote table. This differs from the way that storage engines
for local tables work.
For local database tables, data files are local. For example, if
you create a MyISAM table named
users, the MyISAM handler
creates a data file named users.MYD. A handler
for local tables reads, inserts, deletes, and updates data in
local data files, and rows are stored in a format particular to
the handler. To read rows, the handler must parse data into
columns. To write rows, column values must be converted to the row
format used by the handler and written to the local data file.
With the MySQL FEDERATED storage engine, there
are no local data files for a table (for example, there is no
.MYD file). Instead, a remote database stores
the data that normally would be in the table. The local server
connects to a remote server, and uses the MySQL client API to
read, delete, update, and insert data in the remote table. For
example, data retrieval is initiated via a SELECT * FROM
SQL statement.
tbl_name
When a client issues an SQL statement that refers to a
FEDERATED table, the flow of information
between the local server (where the SQL statement is executed) and
the remote server (where the data is physically stored) is as
follows:
The storage engine looks through each column that the
FEDERATEDtable has and constructs an appropriate SQL statement that refers to the remote table.The statement is sent to the remote server using the MySQL client API.
The remote server processes the statement and the local server retrieves any result that the statement produces (an affected-rows count or a result set).
If the statement produces a result set, each column is converted to internal storage engine format that the
FEDERATEDengine expects and can use to display the result to the client that issued the original statement.
The local server communicates with the remote server using MySQL
client C API functions. It invokes
mysql_real_query() to send the
statement. To read a result set, it uses
mysql_store_result() and fetches
rows one at a time using
mysql_fetch_row().
The procedure for using FEDERATED tables is
very simple. Normally, you have two servers running, either both
on the same host or on different hosts. (It is possible for a
FEDERATED table to use another table that is
managed by the same server, although there is little point in
doing so.)
First, you must have a table on the remote server that you want to
access by using a FEDERATED table. Suppose that
the remote table is in the federated database
and is defined like this:
CREATE TABLE test_table (
id INT(20) NOT NULL AUTO_INCREMENT,
name VARCHAR(32) NOT NULL DEFAULT '',
other INT(20) NOT NULL DEFAULT '0',
PRIMARY KEY (id),
INDEX name (name),
INDEX other_key (other)
)
ENGINE=MyISAM
DEFAULT CHARSET=latin1;
The example uses a MyISAM table, but the table
could use any storage engine.
Next, create a FEDERATED table on the local
server for accessing the remote table:
CREATE TABLE federated_table (
id INT(20) NOT NULL AUTO_INCREMENT,
name VARCHAR(32) NOT NULL DEFAULT '',
other INT(20) NOT NULL DEFAULT '0',
PRIMARY KEY (id),
INDEX name (name),
INDEX other_key (other)
)
ENGINE=FEDERATED
DEFAULT CHARSET=latin1
CONNECTION='mysql://fed_user@remote_host:9306/federated/test_table';
(Before MySQL 5.0.13, use COMMENT rather than
CONNECTION.)
The basic structure of this table should match that of the remote
table, except that the ENGINE table option
should be FEDERATED and the
CONNECTION table option is a connection string
that indicates to the FEDERATED engine how to
connect to the remote server.
Note
You can improve the performance of a
FEDERATED table by adding indexes to the
table on the host, even though the tables will not actually be
created locally. The optimization will occur because the query
sent to the remote server will include the contents of the
WHERE clause will be sent to the remote
server and executed locally. This reduces the network traffic
that would otherwise request the entire table from the server
for local processing.
The FEDERATED engine creates only the
test_table.frm file in the
federated database.
The remote host information indicates the remote server to which
your local server connects, and the database and table information
indicates which remote table to use as the data source. In this
example, the remote server is indicated to be running as
remote_host on port 9306, so there must be a
MySQL server running on the remote host and listening to port
9306.
The general form of the connection string in the
CONNECTION option is as follows:
scheme://user_name[:password]@host_name[:port_num]/db_name/tbl_name
Only mysql is supported as the
scheme value at this point; the
password and port number are optional.
Sample connection strings:
CONNECTION='mysql://username:password@hostname:port/database/tablename' CONNECTION='mysql://username@hostname/database/tablename' CONNECTION='mysql://username:password@hostname/database/tablename'
The use of CONNECTION for specifying the
connection string is nonoptimal and is likely to change in future.
Keep this in mind for applications that use
FEDERATED tables. Such applications are likely
to need modification if the format for specifying connection
information changes.
Because any password given in the connection string is stored as
plain text, it can be seen by any user who can use
SHOW CREATE TABLE or
SHOW TABLE STATUS for the
FEDERATED table, or query the
TABLES table in the
INFORMATION_SCHEMA database.
The following items indicate features that the
FEDERATED storage engine does and does not
support:
The remote server must be a MySQL server. Support by
FEDERATEDfor other database engines may be added in the future.The remote table that a
FEDERATEDtable points to must exist before you try to access the table through theFEDERATEDtable.It is possible for one
FEDERATEDtable to point to another, but you must be careful not to create a loop.There is no support for transactions.
A
FEDERATEDtable does not support indexes per se. Because access to the table is handled remotely, it is the remote table that supports the indexes. Care should be taken when creating aFEDERATEDtable since the index definition from an equivalentMyISAMor other table may not be supported. For example, creating aFEDERATEDtable with an index prefix onVARCHAR,TEXTorBLOBcolumns will fail. The following definition inMyISAMis valid:CREATE TABLE `T1`(`A` VARCHAR(100),UNIQUE KEY(`A`(30))) ENGINE=MYISAM;
The key prefix in this example is incompatible with the
FEDERATEDengine, and the equivalent statement will fail:CREATE TABLE `T1`(`A` VARCHAR(100),UNIQUE KEY(`A`(30))) ENGINE=FEDERATED CONNECTION='MYSQL://127.0.0.1:3306/TEST/T1';
If possible, you should try to separate the column and index definition when creating tables on both the remote server and the local server to avoid these index issues.
Internally, the implementation uses
SELECT,INSERT,UPDATE, andDELETE, but notHANDLER.The
FEDERATEDstorage engine supportsSELECT,INSERT,UPDATE,DELETE, and indexes. It does not supportALTER TABLE, or any Data Definition Language statements that directly affect the structure of the table, other thanDROP TABLE. The current implementation does not use prepared statements.FEDERATEDacceptsINSERT ... ON DUPLICATE KEY UPDATEstatements, but if a duplicate-key violation occurs, the statement fails with an error.Performance on a
FEDERATEDtable when performing bulk inserts (for example, on aINSERT INTO ... SELECT ...statement) is slower than with other table types because each selected row is treated as an individualINSERTstatement on the federated table.Before MySQL 5.0.46, for a multiple-row insert into a
FEDERATEDtable that refers to a remote transactional table, if the insert failed for a row due to constraint failure, the remote table would contain a partial commit (the rows preceding the failed one) instead of rolling back the statement completely. This occurred because the rows were treated as individual inserts.As of MySQL 5.0.46,
FEDERATEDperforms bulk-insert handling such that multiple rows are sent to the remote table in a batch. This provides a performance improvement. Also, if the remote table is transactional, it enables the remote storage engine to perform statement rollback properly should an error occur. This capability has the following limitations:The size of the insert cannot exceed the maximum packet size between servers. If the insert exceeds this size, it is broken into multiple packets and the rollback problem can occur.
Bulk-insert handling does not occur for
INSERT ... ON DUPLICATE KEY UPDATE.
There is no way for the
FEDERATEDengine to know if the remote table has changed. The reason for this is that this table must work like a data file that would never be written to by anything other than the database system. The integrity of the data in the local table could be breached if there was any change to the remote database.Any
DROP TABLEstatement issued against aFEDERATEDtable drops only the local table, not the remote table.FEDERATEDtables do not work with the query cache.
Some of these limitations may be lifted in future versions of the
FEDERATED handler.
The ARCHIVE storage engine is used for storing
large amounts of data without indexes in a very small footprint.
The ARCHIVE storage engine is included in MySQL
binary distributions. To enable this storage engine if you build
MySQL from source, invoke configure with the
--with-archive-storage-engine option.
To examine the source for the ARCHIVE engine,
look in the sql directory of a MySQL source
distribution.
You can check whether the ARCHIVE storage engine
is available with this statement:
mysql> SHOW VARIABLES LIKE 'have_archive';
When you create an ARCHIVE table, the server
creates a table format file in the database directory. The file
begins with the table name and has an .frm
extension. The storage engine creates other files, all having names
beginning with the table name. The data and metadata files have
extensions of .ARZ and
.ARM, respectively. An
.ARN file may appear during optimization
operations.
The ARCHIVE engine supports
INSERT and
SELECT, but not
DELETE,
REPLACE, or
UPDATE. It does support
ORDER BY operations,
BLOB columns, and basically all but
spatial data types (see Section 11.12.4.1, “MySQL Spatial Data Types”).
The ARCHIVE engine uses row-level locking.
Storage: Rows are compressed as
they are inserted. The ARCHIVE engine uses
zlib lossless data compression (see
http://www.zlib.net/). You can use
OPTIMIZE TABLE to analyze the table
and pack it into a smaller format (for a reason to use
OPTIMIZE TABLE, see later in this
section). Beginning with MySQL 5.0.15, the engine also supports
CHECK TABLE. There are several types
of insertions that are used:
An
INSERTstatement just pushes rows into a compression buffer, and that buffer flushes as necessary. The insertion into the buffer is protected by a lock. ASELECTforces a flush to occur, unless the only insertions that have come in wereINSERT DELAYED(those flush as necessary). See Section 12.2.5.2, “INSERT DELAYEDSyntax”.A bulk insert is visible only after it completes, unless other inserts occur at the same time, in which case it can be seen partially. A
SELECTnever causes a flush of a bulk insert unless a normal insert occurs while it is loading.
Retrieval: On retrieval, rows are
uncompressed on demand; there is no row cache. A
SELECT operation performs a complete
table scan: When a SELECT occurs, it
finds out how many rows are currently available and reads that
number of rows. SELECT is performed
as a consistent read. Note that lots of
SELECT statements during insertion
can deteriorate the compression, unless only bulk or delayed inserts
are used. To achieve better compression, you can use
OPTIMIZE TABLE or
REPAIR TABLE. The number of rows in
ARCHIVE tables reported by
SHOW TABLE STATUS is always accurate.
See Section 12.5.2.5, “OPTIMIZE TABLE Syntax”,
Section 12.5.2.6, “REPAIR TABLE Syntax”, and
Section 12.5.5.33, “SHOW TABLE STATUS Syntax”.
Additional resources
A forum dedicated to the
ARCHIVEstorage engine is available at http://forums.mysql.com/list.php?112.
The CSV storage engine stores data in text files
using comma-separated values format. It is unavailable on Windows
until MySQL 5.1.
The CSV storage engine is included in MySQL
binary distributions (except on Windows). To enable this storage
engine if you build MySQL from source, invoke
configure with the
--with-csv-storage-engine option.
To examine the source for the CSV engine, look in
the sql/examples directory of a MySQL source
distribution.
When you create a CSV table, the server creates a
table format file in the database directory. The file begins with
the table name and has an .frm extension. The
storage engine also creates a data file. Its name begins with the
table name and has a .CSV extension. The data
file is a plain text file. When you store data into the table, the
storage engine saves it into the data file in comma-separated values
format.
mysql>CREATE TABLE test (i INT NOT NULL, c CHAR(10) NOT NULL)->ENGINE = CSV;Query OK, 0 rows affected (0.12 sec) mysql>INSERT INTO test VALUES(1,'record one'),(2,'record two');Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql>SELECT * FROM test;+------+------------+ | i | c | +------+------------+ | 1 | record one | | 2 | record two | +------+------------+ 2 rows in set (0.00 sec)
If you examine the test.CSV file in the
database directory created by executing the preceding statements,
its contents should look like this:
"1","record one" "2","record two"
This format can be read, and even written, by spreadsheet applications such as Microsoft Excel or StarOffice Calc.
The CSV storage engine does not support indexing.
The BLACKHOLE storage engine acts as a
“black hole” that accepts data but throws it away and
does not store it. Retrievals always return an empty result:
mysql>CREATE TABLE test(i INT, c CHAR(10)) ENGINE = BLACKHOLE;Query OK, 0 rows affected (0.03 sec) mysql>INSERT INTO test VALUES(1,'record one'),(2,'record two');Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql>SELECT * FROM test;Empty set (0.00 sec)
The BLACKHOLE storage engine is included in MySQL
binary distributions. To enable this storage engine if you build
MySQL from source, invoke configure with the
--with-blackhole-storage-engine option.
To examine the source for the BLACKHOLE engine,
look in the sql directory of a MySQL source
distribution.
When you create a BLACKHOLE table, the server
creates a table format file in the database directory. The file
begins with the table name and has an .frm
extension. There are no other files associated with the table.
The BLACKHOLE storage engine supports all kinds
of indexes. That is, you can include index declarations in the table
definition.
You can check whether the BLACKHOLE storage
engine is available with this statement:
mysql> SHOW VARIABLES LIKE 'have_blackhole_engine';
Inserts into a BLACKHOLE table do not store any
data, but if the binary log is enabled, the SQL statements are
logged (and replicated to slave servers). This can be useful as a
repeater or filter mechanism. For example, suppose that your
application requires slave-side filtering rules, but transferring
all binary log data to the slave first results in too much traffic.
In such a case, it is possible to set up on the master host a
“dummy” slave process whose default storage engine is
BLACKHOLE, depicted as follows:
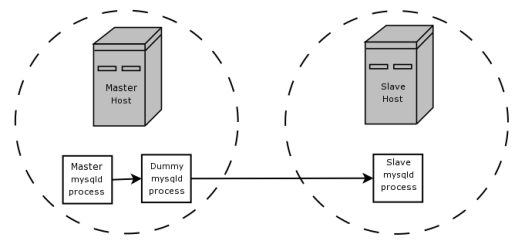
The master writes to its binary log. The “dummy”
mysqld process acts as a slave, applying the
desired combination of replicate-do-* and
replicate-ignore-* rules, and writes a new,
filtered binary log of its own. (See
Section 16.1.2, “Replication and Binary Logging Options and Variables”.) This filtered log is
provided to the slave.
The dummy process does not actually store any data, so there is little processing overhead incurred by running the additional mysqld process on the replication master host. This type of setup can be repeated with additional replication slaves.
INSERT triggers for
BLACKHOLE tables work as expected. However,
because the BLACKHOLE table does not actually
store any data, UPDATE and
DELETE triggers are not activated:
The FOR EACH ROW clause in the trigger definition
does not apply because there are no rows.
Other possible uses for the BLACKHOLE storage
engine include:
Verification of dump file syntax.
Measurement of the overhead from binary logging, by comparing performance using
BLACKHOLEwith and without binary logging enabled.BLACKHOLEis essentially a “no-op” storage engine, so it could be used for finding performance bottlenecks not related to the storage engine itself.